


 PostgreSQL, renowned for its robustness and ACID compliance, relies heavily on Multi-Version Concurrency Control (MVCC) to manage concurrent transactions. While MVCC offers significant advantages, it introduces the concept of dead tuples, which, if left unchecked, can severely impact database performance.
PostgreSQL, renowned for its robustness and ACID compliance, relies heavily on Multi-Version Concurrency Control (MVCC) to manage concurrent transactions. While MVCC offers significant advantages, it introduces the concept of dead tuples, which, if left unchecked, can severely impact database performance.
This article delves into the intricacies of dead tuples, exploring their formation, performance implications, and effective remediation strategies.
Understanding MVCC and dead tuples
MVCC allows multiple transactions to read and write data concurrently without blocking each other. When a row is updated or deleted, PostgreSQL doesn't immediately overwrite or remove the existing row. Instead, it creates a new version of the row (a new tuple) and marks the old version as dead. These dead tuples remain in the table until they are reclaimed by the VACUUM process.
How dead tuples accumulate
Dead tuples accumulate in a database due to several operations that modify the data. These operations include updates, deletes, and rollbacks. Here's a more detailed look at each of these processes:
- Updates

When a row in a table is updated, the database does not modify the existing tuple directly. Instead, it creates a new tuple with the updated values and marks the old tuple as dead. This approach ensures that the database can maintain consistency and support features like multi-version concurrency control (MVCC). The old tuple remains in the table until it is eventually cleaned up by a process called vacuuming.
- Deletes

When a row is deleted from a table, the database does not immediately remove the row from the physical storage. Instead, it marks the tuple as dead. This marking allows the database to maintain a record of the deleted row for transactional consistency and potential rollback operations. The dead tuple remains in the table until it is cleaned up by the vacuuming process.
- Rollbacks

Transactions that are rolled back can also leave dead tuples behind. When a transaction is rolled back, any changes made during the transaction are undone. However, the tuples that were created or modified during the transaction are not immediately removed. Instead, they are marked as dead. This ensures that the database can maintain a consistent state and support features like MVCC. The dead tuples are eventually cleaned up by the vacuuming process.
Performance implications of dead tuples
The presence of excessive dead tuples can significantly degrade PostgreSQL performance in several ways:
- Increased table size
Dead tuples occupy disk space, leading to larger table sizes. This can result in several performance issues:
- Increased I/O operations: Larger tables require more I/O operations during sequential scans, as the database needs to read through all the tuples, including the dead ones.
- Slower index scans: Indexes that point to dead tuples become larger, which can slow down index scans. The database needs to traverse a larger index to find the relevant data.
- Increased backup and restore times: Larger tables and indexes take more time to back up and restore, as the database needs to process more data.
- Slower sequential scans
Sequential scans must traverse all tuples in a table, including dead ones. This increases the scan time, especially for large tables with a high percentage of dead tuples. The database spends more time reading through unnecessary data, which can slow down query performance.
- Increased index size and scan time
Indexes can contain pointers to dead tuples, increasing their size. Larger indexes require more time to scan, as the database needs to process more entries to find the relevant data. This can slow down queries that rely on index scans.
- Bloated tables and indexes
With prolonged dead tuple accumulation, tables and indexes can become bloated. Bloated tables and indexes lead to inefficient storage and retrieval, as the database needs to manage more data than necessary. This can result in slower query performance and increased storage requirements.
- VACUUM performance
The VACUUM process is responsible for reclaiming dead tuples and freeing up disk space. While VACUUM helps maintain database performance, it also consumes resources. If the number of dead tuples is excessively high, VACUUM operations can become resource-intensive and time-consuming. This can impact overall database performance, as VACUUM competes for resources with other database operations.
- Increased disk I/O
Reading unnecessary dead tuples increases I/O operations, which can become a bottleneck for performance. The database spends more time and resources on disk I/O, which can slow down query execution and overall database performance.
Identifying dead tuples in PostgreSQL
 PostgreSQL provides several tools and methods to identify and monitor dead tuples within your database. These tools help you understand the extent of dead tuple accumulation and take appropriate actions to maintain database performance. Here are some of the key tools and methods:
PostgreSQL provides several tools and methods to identify and monitor dead tuples within your database. These tools help you understand the extent of dead tuple accumulation and take appropriate actions to maintain database performance. Here are some of the key tools and methods:
- pgstattuple extension
- The pgstattuple extension provides detailed statistics about tables, including the number of dead tuples and their percentage. This extension can be very useful for gaining insights into the health of your tables.
- To use the pgstattuple extension, you first need to create the extension in your database:
CREATE EXTENSION pgstattuple;
- Once the extension is created, you can query the statistics for a specific table:
SELECT * FROM pgstattuple('your_table'); - This query will return detailed information about the table, including the number of live tuples, dead tuples, and the percentage of dead tuples.
- pg_stat_user_tables view
- The pg_stat_user_tables system view provides information about table statistics, including the number of dead tuples. This view is part of PostgreSQL's statistics collector, which tracks various metrics about database activity.
- You can query the pg_stat_user_tables view to get information about dead tuples for a specific table:
SELECT relname, n_dead_tup FROM pg_stat_user_tables WHERE relname = 'your_table';
- This query will return the table name and the number of dead tuples for the specified table. You can use this information to monitor dead tuple accumulation and take necessary actions.
- Autovacuum logs
- PostgreSQL's autovacuum daemon automatically runs vacuum operations to reclaim dead tuples and maintain database performance. The autovacuum daemon logs its activities, including the number of dead tuples reclaimed during each vacuum operation.
- You can enable and configure autovacuum logging in the PostgreSQL configuration file (postgresql.conf). For example, you can set the log_autovacuum_min_duration parameter to log autovacuum activities that take longer than a specified duration:
log_autovacuum_min_duration = 0 # Log all autovacuum activities
- Once autovacuum logging is enabled, you can review the PostgreSQL logs to see information about autovacuum activities, including the number of dead tuples reclaimed. This can help you monitor the effectiveness of autovacuum and identify tables with high dead tuple accumulation.
Remediation strategies for managing dead tuples
Effectively managing dead tuples is crucial for maintaining PostgreSQL's performance and preventing database bloat. To address this, a range of remediation strategies can be employed.
- Regular VACUUM operations
- Configure autovacuum: Ensure that the autovacuum daemon is configured to run frequently and aggressively. This helps in regularly cleaning up dead tuples and maintaining database performance.
- Manual VACUUM: For tables with high dead tuple counts, consider running the VACUUM command manually. This can be particularly useful for tables that are heavily updated or deleted.
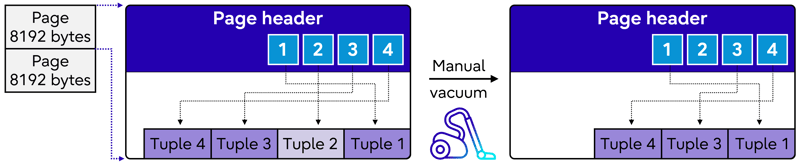
- VACUUM FULL: For aggressive cleanup, use the VACUUM FULL command. This command reclaims more space by rewriting the entire table. However, be aware that VACUUM FULL locks the table, which can impact concurrent access.
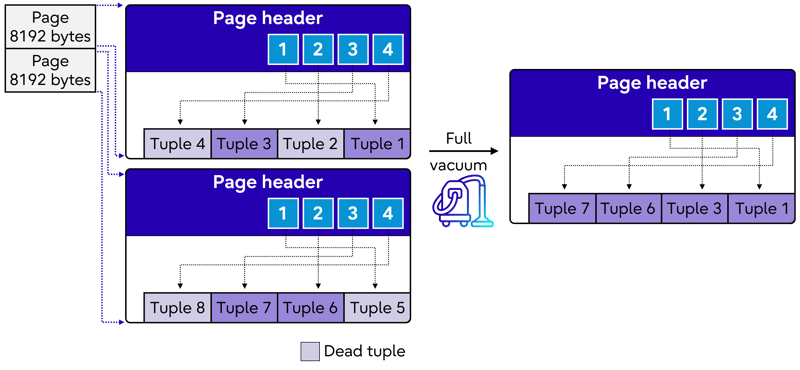
- Analyze table statistics
- Run ANALYZE: Ensure that table statistics are up-to-date by running the ANALYZE command. Accurate statistics help the query planner make optimal decisions, improving query performance.
- Automatic statistics collection: PostgreSQL automatically collects statistics but running ANALYZE manually can be beneficial after significant data changes.
- Tune autovacuum parameters
- Adjust thresholds: Modify the autovacuum_vacuum_threshold and autovacuum_vacuum_scale_factor parameters to trigger VACUUM operations more frequently. This helps in keeping dead tuple accumulation in check.
- Control resource usage: Adjust the autovacuum_max_workers and autovacuum_cost_limit parameters to control the resources allocated to autovacuum operations. This ensures that autovacuum does not interfere with other database activities.
- Increase maintenance memory: Consider increasing the maintenance_work_mem parameter to allocate more memory for maintenance operations like VACUUM and ANALYZE. This can improve the efficiency of these operations.
- Optimize queries and transactions
- Minimize updates and deletes: Reduce the number of updates and deletes to minimize the creation of dead tuples. Where possible, use bulk operations instead of individual row updates or deletes.
- Short transactions: Keep transactions short to reduce the duration of row locks. Long-running transactions can delay the cleanup of dead tuples and impact database performance.
- Index maintenance
- Rebuild indexes: Periodically rebuild indexes to remove pointers to dead tuples. This helps in maintaining index efficiency and improving query performance.
- REINDEX commands: Use the REINDEX or REINDEX CONCURRENTLY commands to rebuild indexes. REINDEX CONCURRENTLY allows for index rebuilding without locking the table, minimizing the impact on concurrent access.
- Monitor and alert
- Track dead tuples: Implement monitoring to track dead tuple counts and VACUUM activity. This helps in identifying tables with high dead tuple accumulation and taking timely action.
- Set up alerts: Configure alerts to notify administrators when dead tuple counts exceed predefined thresholds. This ensures that potential issues are addressed promptly.
- Use pg_repack or similar extensions
- Handle extreme bloat: For very large tables that suffer from extreme bloat, consider using extensions like pg_repack. These extensions can rebuild the table without locking it for extended periods of time, allowing for efficient cleanup and maintenance.
Conclusion
 Dead tuples are a natural consequence of PostgreSQL's MVCC architecture. However, neglecting them can lead to significant performance degradation. By understanding the formation and impact of dead tuples, implementing regular VACUUM operations, tuning autovacuum parameters and optimizing queries and transactions, database administrators can effectively mitigate the performance impact of dead tuples and ensure the long-term health and efficiency of their PostgreSQL databases.
Dead tuples are a natural consequence of PostgreSQL's MVCC architecture. However, neglecting them can lead to significant performance degradation. By understanding the formation and impact of dead tuples, implementing regular VACUUM operations, tuning autovacuum parameters and optimizing queries and transactions, database administrators can effectively mitigate the performance impact of dead tuples and ensure the long-term health and efficiency of their PostgreSQL databases.



