

This feature was initially proposed on the agenda of PGCon 2017 by me and Haribabu Komi, and included in the community discussions that led to its commitment in PostgreSQL 12.
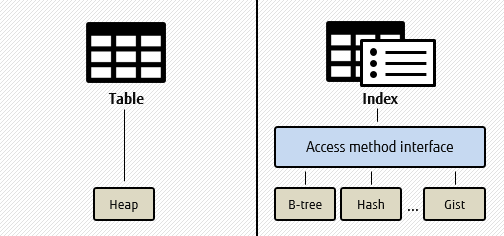
What are table access methods?
It is a feature that allows an alternative implementation for how data in a table should be stored. Until PostgreSQL 11, access methods were provided for index data, to choose different storage methods such as B-Tree or hash, but no similar mechanism was available for tables.
PostgreSQL 12 introduced this feature, so now access methods can be implemented for tables as well as indexes, allowing the selection of different table storage mechanisms.
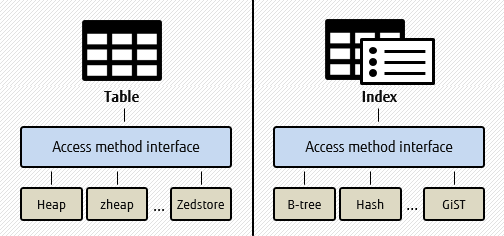
Table access methods expose APIs, which allows PostgreSQL developers to create their own methods. In PostgreSQL 12, the traditional heap format is migrated to a table access method, and is available by default.
How do users use the table access method interface?
To define a table access method, use CREATE ACCESS METHOD with TYPE TABLE. To then have a table use the new access method, specify it in the USING clause in CREATE TABLE, CREATE TABLE AS SELECT, or CREATE MATERIALIZED VIEW. Alternatively, you can specify the default table access method in the postgresql.conf file parameter default _ table _ access _ method.
CREATE ACCESS METHOD heap1 TYPE TABLE HANDLER heap_tableam_handler;
CREATE TABLE tbl1(id int, name text) USING heap1 ...;
The usefulness of table access methods
It was discussed with the development community that additional table access methods needed to be available to make UNDO logs available, and that it is important to make table access methods freely pluggable, similarly to how they work with indexes. The fact that PostgreSQL table storage only supported heap also affected other open source activities in the community, such as zheap and Zedstore.
Advantages and how to use
The appeal of this functionality includes the following:
- Concise, pluggable architecture that is easy to use and PostgreSQL developer-friendly
- Users can specify the access method for each table
- Makes way for both open source and commercial databases
- Co-existence of difference table access methods in the same database
PostgreSQL 12 supports only heap as the table access method, but the next version of PostgreSQL is expected to provide new table access methods, such as columnar and in-memory.
In the future, users will be able to choose the appropriate table access method for their job, such as heap for OLTP operations, columnar table for OLAP operations, and in-memory for ultra-fast search processing. By providing users with an interface that allows them to use a specific table access method, the system will be able to meet a variety of business processing needs.
Is it the same as foreign data wrappers? What is the difference?
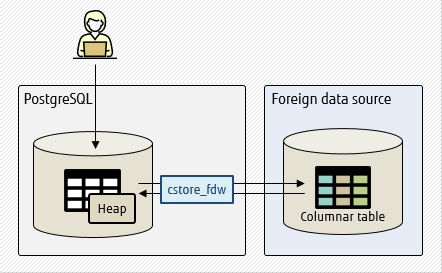
Foreign data wrappers are intended to access foreign data, while table access methods are used to access local data.
For example, suppose you have a requirement to use columnar data in your application. With foreign data wrappers, you would need to use to access a remote server containing the columnar data (in this case using cstore_fdw), which would reduce processing performance.
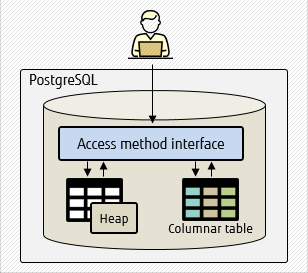
But with table access methods, it is possible to store columnar tables locally, which speeds up processing. Note though, that PostgreSQL 13 does not support table access methods for columnar tables.
In short, foreign data wrappers and table access methods target different needs. The former allows users to access data in a remote server that was never intended to be stored locally, while the latter allows users to store data locally using different supported methods.
With cooperation from the community and support from Fujitsu
The genesis of this feature dates back to 2016, when Álvaro Herrera, a PostgreSQL committer, created a patch for columnar storage. At this same time, Fujitsu also wanted to donate Vertical Clustered Index (our implementation of columnar storage) to the community, and Fujitsu's Haribabu Komi participated in the development to promote this. Later, Robert Haas, another PostgreSQL committer, proposed a generic and extensible approach to table access method rather than focusing on the storage tier.
Fujitsu presented and elaborated the idea during the PGCon 2017 unconference, with a fantastic reaction from the participants. It was one of the highest voted topics in the community. It was not an individual's interest but more of a need at various organizations that made it a popular topic in the unconference. Community members, with the support of current committer Andres Freund, put a lot of effort into development, review, and modification to commit to PostgreSQL 12 in March 2019.
There were two announcements of pluggable storage at PGCon 2019 after the PostgreSQL 12 commit. That was a hot topic, and it was heavily discussed not just in the presentation room but over the casual coffee/snacks as well. One of the presentations was a committers' view, which focused more on architecture and developer's view. On the other hand, my topic touched on usage and need perspective. You can find the presentation here at the PGCon archives.
All members involved in this feature worked hard to modify a large amount of infrastructure code. Even the first patch set provided by Haribabu caused more than 2500 changes to more than 100 files. PostgreSQL's storage is closely linked to other components, making it difficult to investigate and adjust. Achieving this level of functionality was a very complex and labor-intensive task.
Fujitsu provided support to the community to help get this feature committed.
Further development
Possible implementations of table access methods in PostgreSQL 14 and later include, among others, the following:
- An alternative to heap, such as zheap
- Columnar tables, such as Zedstore
- In-memory tables
- Indexed tables
zheap and Zedstore are the two major implementations currently in pipeline. Needless to say, both are very good as far as their functionalities are concerned. We are also following discussions of Zedstore, and if possible, we will also like to either help their cause or work closely with them.
Currently, the table access method API is tuple-based, which limits its capabilities for pluggable storage mechanism, especially for columnar data, but support for UNDO log-based columnar tables and in-memory tables will be added in the future to give you more options and make them easier to use. We also want to have vectorization support for execution engine + table access method APIs in the future.
Wrapping up
The table access method interface introduced in PostgreSQL 12 allows PostgreSQL users to access table data using methods tailored to their requirements. I look forward to seeing more and more PostgreSQL applications with the ability to choose multiple table access methods that match the characteristics of the business.
To start exploring, click the button below.

