Businesses are changing dramatically with the evolution of digital technology, requiring systems to coordinate with various types of data sources and formats to create new value. PostgreSQL allows this via foreign data wrappers, which enable access to foreign data in various formats such as relational databases, NoSQL, and geospatial.
What are foreign data wrappers?
Foreign data wrappers (or FDW) are a type of PostgreSQL extension that provides access to foreign data using SQL statements such as SELECT and UPDATE.
FDWs can be created by using the library published by PostgreSQL and can be customized according to the format of the data to be linked with. Many companies, projects, and individuals have created FDWs in this way. There are nearly 120 types of FDWs available to the public, allowing to access a wide range of data sources.
Foreign data accessible from PostgreSQL
The main categories of foreign data that can be accessed from PostgreSQL include:
- External PostgreSQL systems
- Relational databases such as Oracle, SQL Server, MySQL, etc.
- NoSQL databases such as MongoDB, Redis, Cassandra, etc.
- Columnar databases such as MonetDB, Citus, etc.
- Files in various formats such as CSV, plain text, XML, JSON, ZIP, etc.
- Geospatial information in PostGIS extender
- LDAP
- Big Data stores such as Apache Hadoop, Google BigQuery, Elasticsearch, etc.
- SNS such as Facebook and Twitter, etc.
- Specific web wrappers for Google, DynamoDB, and Telegram, among others
The access point for foreign data is called a data source.
Foreign data wrapper mechanism and usage
In addition to referencing foreign data, some FDWs benefit from a pushdown mechanism to run SQL to update, filter, or sort data in the data source. This section gives an overview of the mechanism and usage of FDW.
Foreign data wrapper mechanism
This section describes how FDWs connect to foreign data sources, and its mechanism in PostgreSQL.
To access a foreign data source, install the corresponding FDW as a PostgreSQL extension and define the foreign data as a foreign table. Foreign data will then be accessible through the FDW via SQL statements.
Access to foreign data source
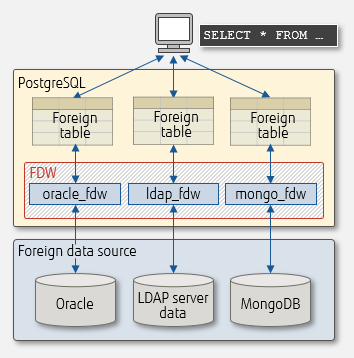
FDWs allow access to various foreign data sources
Process in PostgreSQL
When a client issues an SQL statement that includes a foreign table, the process is run within PostgreSQL according to the following workflow.
FDW execution in PostgreSQL
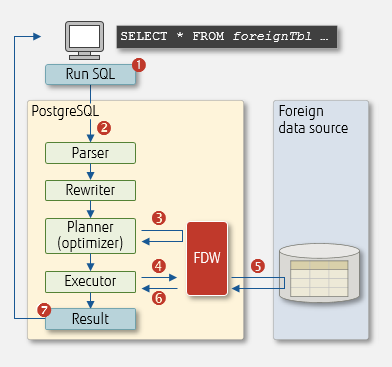
- Client runs the SQL statement specifying a foreign table in the FROM clause
- The SQL statement is parsed and rewritten if necessary
- The planner (optimizer) requests the FDW for an optimal execution plan
- The executor sends a request to the FDW
- The FDW obtains data from the foreign data source
- The FDW converts the result to PostgreSQL internal format and returns to the executor
- The result is returned to the client
Using foreign data wrappers
Before using a FDW, you will need to create related objects - this involves the following:
- installing the FDW corresponding to the data source
- defining the remote server to connect to
- defining the user mapping of users to the foreign server
- creating a foreign table
The following is an example of using the FDW postgres_fdw to link with an external PostgreSQL system. For postgres_fdw, you will need to create the objects in the order shown below on the local side.
Linking to an external PostgreSQL system
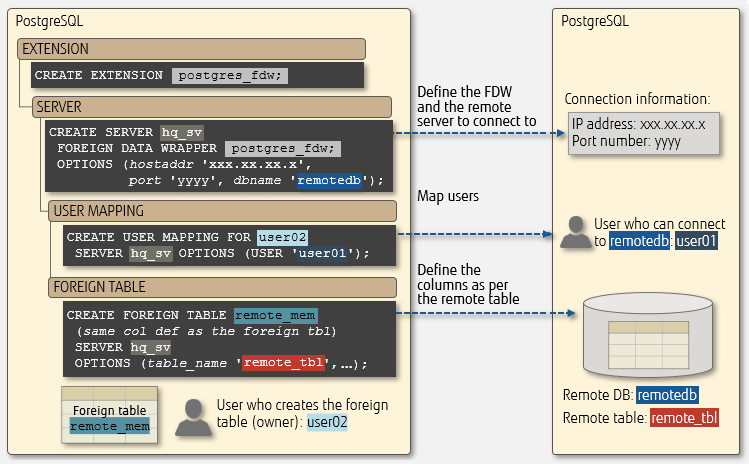
Linking to remote table remote_tbl for user user01
| Object type |
Description |
| EXTENSION |
Create the FDW module as a PostgreSQL extension. |
| SERVER |
Specify the connection information to the remote server and the FDW to use. |
| USER MAPPING |
Associate the remote server with a local user who has privileges to the remote table.
Some FDWs allow a remote user to be specified – this allows you to map local users to remote users if necessary. |
| FOREIGN TABLE |
Create the foreign table on the PostgreSQL side adhering to the same column definition as the remote table. |
One way to verify that an external table has been created is to run the \det+ command and check from the list of external tables. For an example, refer to our article "How to link to Oracle databases using oracle_fdw (part 1)".
The items and formats that can be specified in OPTIONS of CREATE SERVER, CREATE USER MAPPING, and CREATE FOREIGN TABLE vary depending on the FDW used.
Note
In addition to CREATE FOREIGN TABLE, you can also use IMPORT FOREIGN SCHEMA to create foreign tables using the same column definition as the remote table.
This is useful if you want to create multiple foreign tables in the same schema, as foreign tables will be created locally on a per-schema basis according to the remote side.
Our article "How to link to Oracle databases using oracle_fdw" expands on this.
Using pushdown
FDW has a mechanism called pushdown, which allows the remote execution of clauses in client SQL statements, such as WHERE and ORDER BY. For example, pushdown of WHERE has the effect of reducing communication bottlenecks, because the target data is filtered on the remote side and thus reduces the amount of data transferred between local and remote systems. In a process where 5 out of 1,000 rows of foreign data are extracted by specifying the WHERE clause, the data transfer volume is reduced by 99.5%.
Using FDW without pushdown
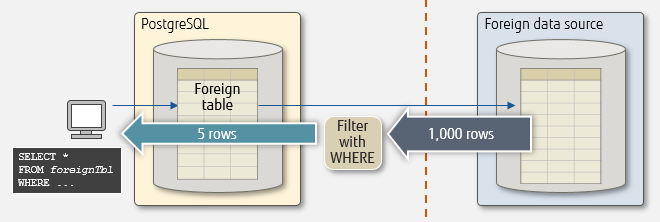
Using FDW with pushdown
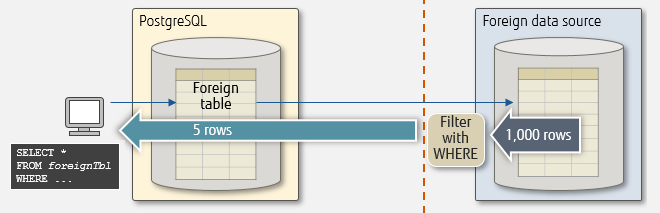
Clauses available for pushdown differ depending on the FDW. Also, some combination of clauses may not be eligible for pushdown. Be sure to verify the specifications by referring to the documentation of the FDW being used.
Key points for using FDW
The points below refer mainly to postgres_fdw, and may differ for other FDWs – if you plan to use a different FDW, please check its documentation accordingly.
Controlling update transactions
These are the points to keep in mind when using update transactions on foreign tables.
- Timing of COMMIT on the remote side
Updates made to the foreign table on the local side are reflected on the remote side when a COMMIT is issued on the local side. If the update is successful and the COMMIT is completed on the remote side, it is also committed on the local side. The same is true for ROLLBACK.
- Transaction isolation level
Even if the SQL statement issued to the foreign table is a single SQL statement, multiple SQL statements may be issued on the remote side via FDW. In this case, the remote side operates with REPEATABLE READ or SERIALIZABLE to maintain transaction consistency. If the transaction isolation levels do not match between the sides, transaction execution results may differ.
Refreshing statistics
Up-to-date statistics are important for optimal execution planning, and for this reason autovacuum runs ANALYZE on regular tables to refresh the statistics. But for foreign tables, ANALYZE must be run separately. Note that there are FDWs that can refresh the statistics when accessing the foreign table.
Data type conversion when accessing the remote system
FDWs automatically convert data when transferring between the foreign table and its remote counterpart, but in some cases the conversion may not take place correctly if the remote data source is other than PostgreSQL.
For example, in VARCHAR(n), Oracle treats 'n' as the number of bytes, while PostgreSQL treats it as the number of characters. This may cause an error if the capacity is exceeded when data is converted.
Using FDW with partitioning
By combining FDW with table partitioning, foreign data distributed and stored on multiple servers can be aggregated into a partitioned table via foreign tables (partitions). For example, sales information in branches can be aggregated to a partition table on a server at the head office, where data can be efficiently referenced and analyzed.
Using FDW with partitioned tables
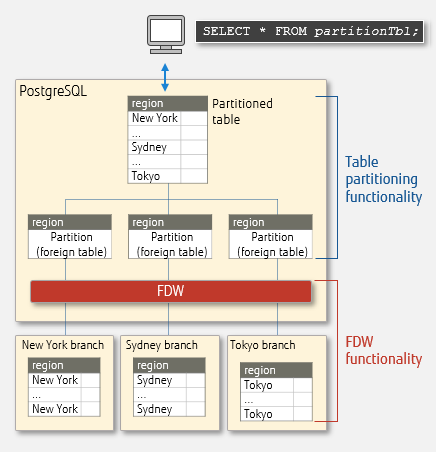
Partitioning improves search performance and maintainability by dividing tables. To learn more, read our article "Improving database performance using partitioning — step-by-step".
Performance of data manipulation
Due to network latency and communication frequency, the FDW is slow to manipulate data in external tables. Therefore, it is important to verify that there are no performance issues when using FDWs.
In PostgreSQL, the performance of FDWs improves with each successive version. For example, PostgreSQL 14 allows postgres_fdw to speed up bulk inserts on foreign tables. Therefore, it is also important to consider using the latest version of PostgreSQL.
Indexes on foreign tables
You cannot create an index on a foreign table. For example,CREATE INDEX ON remote_mem (column name); may result in an error message similar to the following:
ERROR: cannot create index on foreign table "remote_mem"
ERROR: cannot create index on relation "remote_mem"
Use scenario: Providing new services using IoT data
By giving access to data in such a variety of formats, new services can be extended using existing systems. For example, new services can be created by combining user information in existing core databases with IoT data such as location information and sensor information.
Summary
FDW allows access to various data sources and enables execution of SQL on foreign data. It is important to note that support for write SQL and pushdown differs for each FDW.
The following is a summary of popular FDWs and their feature support.
| Data source |
FDW |
Version |
Reference
SQL |
Update
SQL |
Pushdown support |
WHERE
clause |
ORDER BY
clause |
JOIN
clause |
| PostgreSQL |
postgres_fdw |
Packaged in PostgreSQL 11.1 |
Yes |
Yes |
Yes |
Yes |
Yes |
| CSV |
file_fdw |
Packaged in PostgreSQL 11.1 |
Yes |
No |
No |
No |
No |
| Oracle |
oracle_fdw |
2.1.0 |
Yes |
Yes |
Yes |
Yes |
Yes |
| MySQL |
mysql_fdw |
2.5.3 |
Yes |
Yes |
Yes |
No |
No |
| Microsoft SQL Server |
tds_fdw |
1.0.8 |
Yes |
No |
Yes |
No |
No |
| MongoDB |
mongo_fdw |
5.1.0 |
Yes |
Yes |
Yes |
No |
No |
| LDAP |
ldap_fdw |
0.1.1 |
Yes |
No |
No |
No |
No |
| Apache Hadoop |
hdfs_fdw |
2.0.5 |
Yes |
No |
Yes |
No |
No |
| Citus |
cstore_fdw |
1.7.0 |
Yes |
No |
No |
No |
No |
| ODBC |
odbc_fdw |
0.5.1 |
Yes |
No |
Yes |
No |
No |
| Redis |
redis_fdw |
1.0.0 |
Yes |
Yes |
Yes |
No |
No |
The URLS below lists FDWs available for PostgreSQL:
(the examples in this article have been validated in PostgreSQL 11.1)







