



Performance bottlenecks, missing features, and subtle bugs are all waiting to be addressed by contributors who are ready to dig in.
In this post, we share the practical lessons we have learned from working on PostgreSQL logical replication: what to look for, how to test, and what pitfalls to watch out for on both the publisher and subscriber sides. Whether you are new to contributing or a seasoned developer looking for your next project, we hope this guide gives you a useful head start.
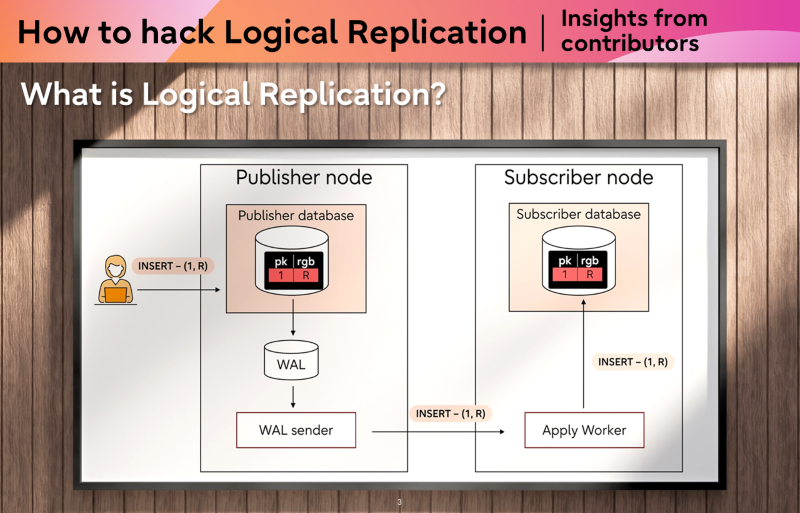
What Is Logical Replication?
 Before diving into the details, here is a quick refresher. Logical replication uses a publish-and-subscribe model. On the publisher side, you create a publication to expose a set of tables:
Before diving into the details, here is a quick refresher. Logical replication uses a publish-and-subscribe model. On the publisher side, you create a publication to expose a set of tables:
CREATE PUBLICATION mypub FOR TABLE users;
On the subscriber side, you connect to that publication:
CREATE SUBSCRIPTION mysub
CONNECTION 'host=192.168.1.100 dbname=postgres user=repuser password=rep123'
PUBLICATION mypub;
From that point on, changes made on the publisher are streamed and applied on the subscriber. Simple in concept, but the implementation has many moving parts.

Changes flow from publisher to subscriber through WAL, decoding, and apply processes
Why contribute to Logical Replication?
 As adoption grows, so do expectations. Users rely on logical replication for increasingly critical workloads, yet several challenges remain: performance bottlenecks in decoding and apply paths, and the lack of features that other databases already have. There are manyu opportunities for contributors to make impactful improvements
As adoption grows, so do expectations. Users rely on logical replication for increasingly critical workloads, yet several challenges remain: performance bottlenecks in decoding and apply paths, and the lack of features that other databases already have. There are manyu opportunities for contributors to make impactful improvements
Contributions to logical replication generally fall into four categories:
- Performance improvements
Reducing latency, lock contention, and unnecessary work
- Bug fixes
Catching regressions and edge cases before users hit them in production
- Code refactoring
Making the codebase easier to read and extend
- New features
Adding capabilities that users need

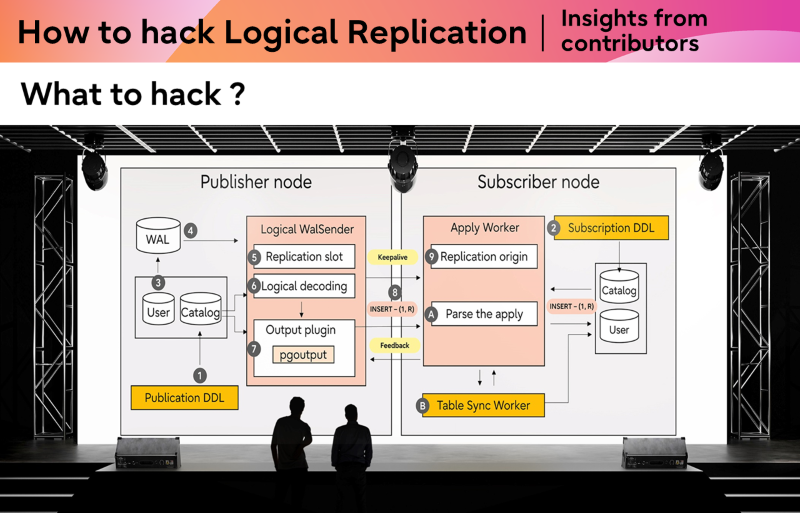
End-to-end logical replication flow
Understanding the system as a whole
Rather than thinking in terms of individual files or functions, it is more effective to view logical replication as a pipeline of stages, from WAL generation through to decoding, streaming, apply workers, and synchronization.
Each stage has distinct responsibilities, and changes in one area often have ripple effects elsewhere. Understanding these relationships is key to making safe and effective contributions.
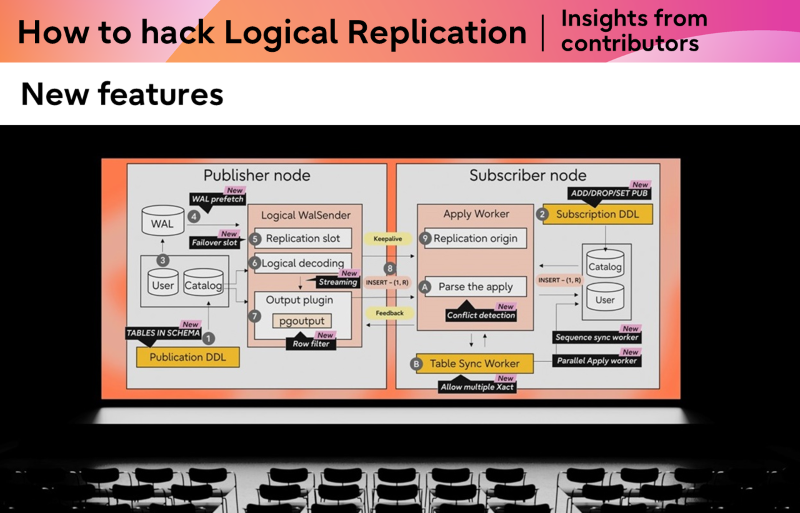
Recent and proposed features continue to expand logical replication capabilities, but they also increase complexity and the need for careful design across components.

Recent and proposed features continue to expand logical replication capabilities, but they also increase complexity and the need for careful design across components.
We will walk through each of these below.
Performance focus on eliminating wasted work
 Performance bottlenecks in logical replication usually hide in hot paths, profiling is the fastest way to find the work that doesn’t need to happen
Performance bottlenecks in logical replication usually hide in hot paths, profiling is the fastest way to find the work that doesn’t need to happen
Performance work starts with focusing on performance-sensitive process, where performance friction exsists, such as locks, latency, and slow SQL. It also includes generating profiles by regularly running perf_record and perf_report to find where time is being spent during decoding and apply, and setting up automated performance test pipelines.
Measuring publisher-side decoding
A useful approach for measuring publisher throughput is:
CREATE PUBLICATION mypub FOR TABLE users;
SELECT pg_create_logical_replication_slot('origin', 'plugin');
SELECT pg_current_wal_lsn();
Then run a workload and measure how long it takes to consume the WAL:
-o proto_version=3 \
-o publication_names=mypub -f /dev/null
Measuring subscriber-side apply
To measure apply latency end-to-end:
On Publisher:
CREATE PUBLICATION mypub FOR TABLE users;
On Subscriber:
CREATE SUBSCRIPTION mysub .. PUBLICATION mypub WITH (enable=false);
ALTER SUBSCRIPTION mysub .. ENABLE;
-- Count the time until the apply worker catches up.

Key takeaway
Profile before you optimize. The biggest gains often come from eliminating unnecessary work in existing code paths, not from adding new logic.
A real example of reducing unnecessary relcache access
The best optimizations often come from deleting work, especially when it runs even for changes that won’t be replicate
During one of our walsender tests, we noticed something unexpected in the profile output:
|--11.84%-- get_rel_sync_entry
|--4.76%-- get_rel_relispartition
|--4.70%-- get_rel_relkind
The issue was that these functions were being called unconditionally, even for changes that were never going to be replicated. By restructuring the code to skip these lookups when they are not needed, we eliminated the overhead.
This became Commit 6ce1608 — Reduce relcache access in WAL sender streaming logical changes.
The lesson: when profiling, look for work being done unnecessarily. Conditional checks on hot paths matter.
Key takeaway
Look for work done unconditionally. Even small function calls in hot paths can have a measurable performance impact when executed repeatedly.
Bug fixes
Replication bugs are rarely isolated, they often appear at the boundaries where features interact
Finding fresh bugs
The best bugs to fix are the freshest ones. We recommend two sources:
- PostgreSQL BuildFarm Recent Failures: Catch regressions shortly after a new commit lands
- PostgreSQL Patch Tester: Identify issues introduced by in-progress patches
Catching a bug soon after the responsible commit makes it much easier to understand what changed and why.
Analysing feature intersections
 When a new feature is committed, it is worth asking: does this interact with logical replication? If so, there is a good chance the new code path was not fully tested against replication scenarios.
When a new feature is committed, it is worth asking: does this interact with logical replication? If so, there is a good chance the new code path was not fully tested against replication scenarios.
A concrete example is the MERGE command. When we analysed its addition to PostgreSQL, we realized it did not correctly check for replica identity on target relations. An UPDATE or DELETE action inside a MERGE requires replica identity to be set. Without it, replication can silently break.
The fix is described in Commit fc6600f:
When executing a MERGE, check that the target relation supports all
actions mentioned in the MERGE command. Specifically, check that it
has a REPLICA IDENTITY if it publishes updates or deletes and the
MERGE command contains update or delete actions. Failing to do this
can silently break replication.
Author: Zhijie Hou houzj.fnst@fujitsu.com
Key takeaway
Assume new features affect replication. Even unrelated SQL features can introduce replication correctness issues if not carefully validated.
Code refactoring
Refactoring work may not be as visible as new features, but it pays dividends over time. Good refactoring:
- Reduces a considerable amount of code duplication. Easier to read and maintain.
- Extracts duplicate code into a centralized function. Reduces maintenance burden by eliminating the need to update multiple places when adding common features.
- Refactors for better understandability. Makes it easier for future developers to build additional functionality on top.
If you are new to the codebase, refactoring is also a great way to get familiar with how things work, and it is genuinely appreciated by maintainers.
Hacking publication features
DDL changes are easy to code but hard to name. Users remember semantics, not implementation details.
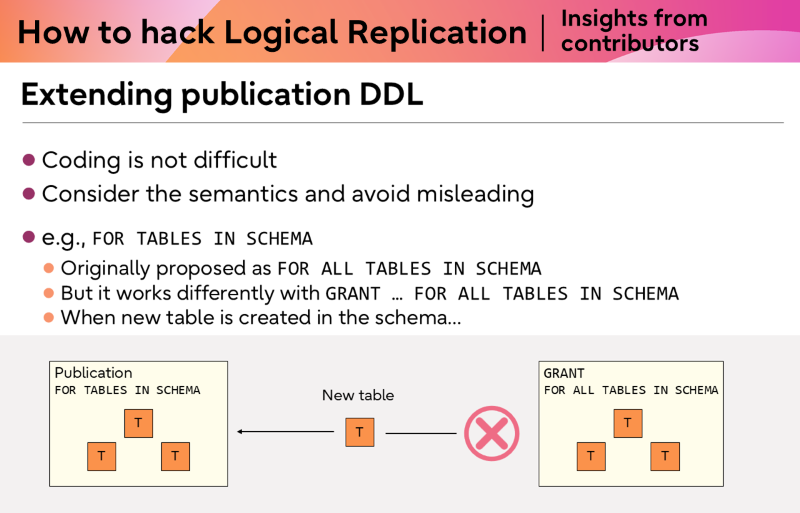
Extending publication DDL: Think hard about semantics
 When you extend the CREATE PUBLICATION or ALTER PUBLICATION syntax, the coding is often straightforward. You typically need to modify gram.y, publicationcmd.c, and pg_publication.c. The harder part is making sure the semantics are clear and not misleading.
When you extend the CREATE PUBLICATION or ALTER PUBLICATION syntax, the coding is often straightforward. You typically need to modify gram.y, publicationcmd.c, and pg_publication.c. The harder part is making sure the semantics are clear and not misleading.
A good example is the FOR TABLES IN SCHEMA clause. This links all tables in a specified schema to the publication. Crucially, any tables created after the publication is made are automatically included.
We originally proposed the syntax FOR ALL TABLES IN SCHEMA. We changed it because GRANT … FOR ALL TABLES IN SCHEMA uses similar phrasing but behaves differently: new tables are not automatically included after a GRANT. Our feature works the opposite way. To avoid confusion, we aligned the naming accordingly.
When a new table is created in the schema:

Comparison of publication DDL semantics
When working on syntax, ask yourself:
- Is the new syntax consistent with existing PostgreSQL grammar?
- Does any keyword imply different semantics than what the feature actually provides?
- Will users misunderstand the scope or future behaviour?
Restriction bypass: Lazy evaluation may be better
 When adding restrictions to publication features, it can be tempting to validate everything at the DDL level during CREATE PUBLICATION or ALTER PUBLICATION. For some constraints, this works well. For others, it creates an impossible maintenance burden.
When adding restrictions to publication features, it can be tempting to validate everything at the DDL level during CREATE PUBLICATION or ALTER PUBLICATION. For some constraints, this works well. For others, it creates an impossible maintenance burden.
Row filtering is a good example. The WHERE clause in CREATE PUBLICATION … WHERE … must only reference replica identity columns for UPDATE/DELETE operations, because the walsender only reconstructs those column values when decoding old tuples. INSERT is not restricted because all column values are always available.
If we tried to validate all combinations at DDL time, we would need to detect violations across DROP INDEX, ALTER TABLE … REPLICA IDENTITY, ATTACH PARTITION, and more. The scope of affected code grows unreasonably.
Instead, we chose lazy evaluation: the check happens at the time changes are actually streamed, rather than at DDL time. This keeps the validation logic in one place and provides a reliable safeguard against data inconsistency. When you add restrictions, remember that there will always be code paths that can bypass a DDL-only check.
Key takeaway
Not all validation belongs at DDL time. If enforcing rules requires touching many subsystems, runtime validation is often the safer and more maintainable choice.
Upgrade and downgrade compatibility
 Mixed-version replication is a feature, and it means every change needs a graceful fallback for older node
Mixed-version replication is a feature, and it means every change needs a graceful fallback for older node
Logical replication allows the publisher and subscriber to run different major versions of PostgreSQL. This is one of its most useful features, but it also means that every new feature you add must degrade gracefully when talking to an older node.
The logical replication protocol has a generation number that is incremented when a new capability is added. Older nodes will not recognize newer protocol generations, so the code must preserve the old communication path.
An example from recent work involves table synchronization in PostgreSQL 19. The tablesync worker calls an SQL function on the publisher to determine which columns need to be copied. When we optimized this function's signature, we had to keep the old API path intact for the case where the publisher is PostgreSQL 18 or earlier. The code uses a server_version variable and branches accordingly.
Test with different versions. Run your changes against older publishers and subscribers to make sure nothing breaks silently.
Catalog lookups in output plugins
This is one of the trickier areas of logical replication, and the source of several subtle bugs.
Logical decoding uses a historic snapshot, the decoder process only sees objects that existed at the time the decoding (or replication) started. This means that objects created or dropped after the snapshot was taken are invisible to the decoder.
Example 1: ALTER SUBSCRIPTION … SET PUBLICATION
When a subscriber changes its list of publications using ALTER SUBSCRIPTION … SET PUBLICATION, the apply worker disconnects, exits, then reconnects. In older versions, this could produce the following error:
ERROR: publication "pub2" does not exist
The cause: if the replication origin was not recently updated and decoding restarted before pub2 was created, the walsender would try to look up pub2 using the historic snapshot from whose perspective, it did not yet exist.
The fix allows a publication mismatch during restart, so the error is no longer raised even if a publication cannot be found in the historic snapshot.

Timeline showing replication failure when a newly created publication is invisible in a historic snapshot
Example 2: Row filters and historic snapshots
Row filters (CREATE PUBLICATION … WHERE …) only permit immutable, built-in functions. This restriction exists precisely because of the historic snapshot.
Consider a filter that uses a function defined in an extension. If that extension is later dropped, the walsender returns an error when it tries to call the missing function. Even if the extension is reinstalled, replication cannot resume, the walsender's historic snapshot cannot see the new version of the extension.

Timeline showing row filter limitations
This is why manually created functions are prohibited in row filters: the behaviour they produce can be unpredictable and unrecoverable.
Key takeaway
Debug with the snapshot in mind. Logical decoding sees a historic view of the catalog, not the current state, this is a common source of subtle bugs.
Hacking the subscriber
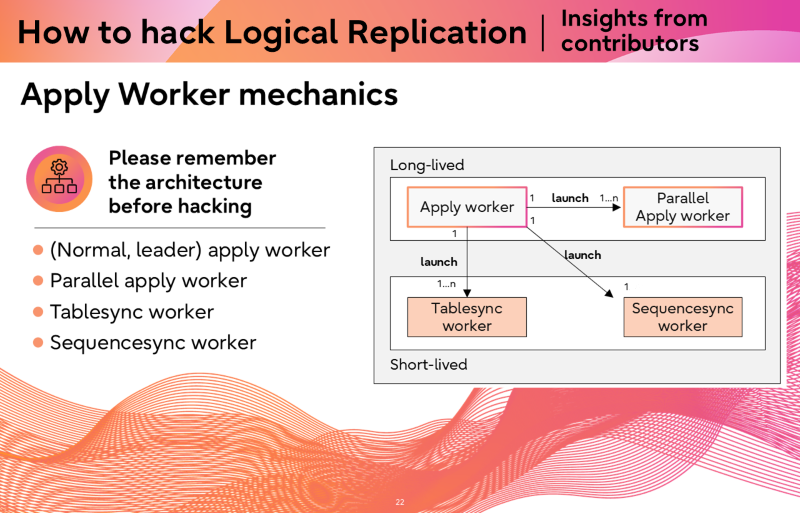
On the subscriber side, replication is executed by multiple worker types, each with different responsibilities and lifecycles.
Understand the architecture first
Before you change anything on the subscriber side, you need to understand the process model. There are four worker types:
| Worker | Lifetime | Role |
| Apply worker (leader) | Long-lived | Connects to publisher, receives and applies changes, maintains replication origin |
| Parallel apply worker | Long-lived (reused) | Processes streamed in-progress transactions in parallel |
|
Tablesync worker |
Short-lived | Runs COPY for initial data sync, then catches up and exits |
| Sequencesync worker | Short-lived | Copies current sequence values; no catch-up phase |
Missing one execution path when modifying these workers is a very common source of bugs.

Overview of subscriber worker architecture, distinguishing long-lived apply processes from short-lived sync workers
Be careful when adding a new worker type
 When a new worker type is needed , as with the sequencesync worker coming in PostgreSQL 19 or the parallel apply worker added in PostgreSQL 16, existing code is your best reference. We made mistakes here ourselves. Two examples involving the parallel apply worker:
When a new worker type is needed , as with the sequencesync worker coming in PostgreSQL 19 or the parallel apply worker added in PostgreSQL 16, existing code is your best reference. We made mistakes here ourselves. Two examples involving the parallel apply worker:
Lock timeout handling (e41d954): The lock timeout is implemented via SIGINT. Existing workers such as the normal apply worker and tablesync worker set a specific handler for this signal. The parallel apply worker used SIGINT for a different purpose and set a different handler, causing lock timeout signals to be silently ignored.
Replication origin advance (1528b0d): The normal apply worker was fixed to add a process exit callback ensuring the replication origin is not advanced if the transaction fails to apply. We did not port this fix to the parallel apply worker. The result: a failed transaction could be marked as applied and would never be retried.
Read existing code before writing new code. Chesterton's Fence applies here, if something is done a particular way in three existing workers, there is probably a good reason.
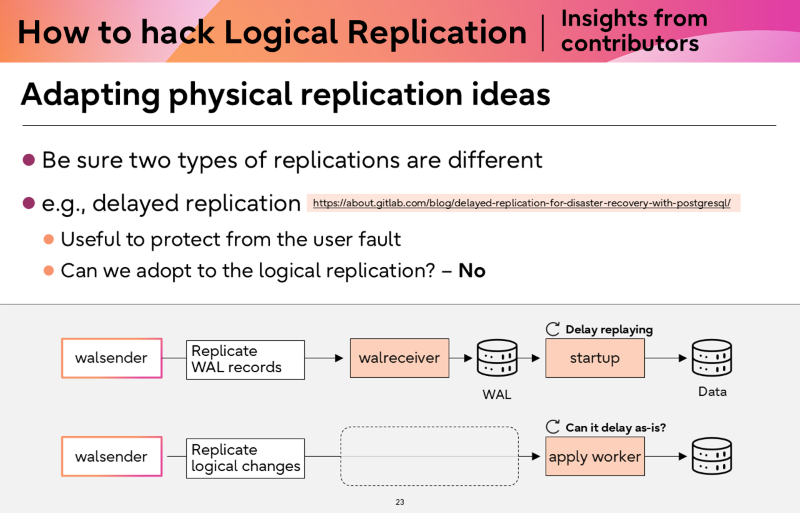
Not everything from physical replication translates
 It is tempting to look at physical replication features and ask "can we do this for logical too?" Sometimes the answer is yes. Often it is more complicated.
It is tempting to look at physical replication features and ask "can we do this for logical too?" Sometimes the answer is yes. Often it is more complicated.
Delayed replication is a good example. In physical replication, recovery_min_apply_delay allows the standby to delay WAL replay by a specified time, giving a window to detect and recover from accidental changes. The delay happens in the startup process, while the walreceiver continues receiving and flushing WAL independently.
For logical replication, these processes are not separated. There is a single apply worker that both receives and applies changes. If it sleeps to implement a delay, it cannot communicate with the publisher, which causes timeouts. Additionally, the publisher must retain all WAL records until changes are confirmed as applied, a three-hour delay could mean retaining three hours of WAL unconditionally, risking disk exhaustion.
For these reasons, we concluded that delayed replication cannot be directly adopted for logical replication in its current form. When adapting a physical replication concept, think carefully about the architectural differences.

Comparison of physical and logical replication
Focus on streaming mode
Streaming mode, introduced in PostgreSQL 14, is the right target for optimization work. It replicates in-progress transactions to the subscriber before they commit, significantly reducing lag for large transactions. It is enabled by default.
The parallel apply worker is a good example of building on streaming mode. Before investing effort in optimizing the non-streaming (spill-to-disk) path, ask whether the improvement would still be relevant when streaming is enabled. In most cases, the answer is that streaming is where your effort will have the greatest impact.
Summary
 Logical replication is one of the most active areas of PostgreSQL development, and one of the most impactful places to contribute. Here are the key takeaways from our experience:
Logical replication is one of the most active areas of PostgreSQL development, and one of the most impactful places to contribute. Here are the key takeaways from our experience:
- Profile before optimizing. Use perf and structured performance tests to find real bottlenecks.
- Track fresh failures.BuildFarm and Patch Tester are your friends for catching new bugs early.
- Analyse feature intersections. New commits often have unexplored interactions with logical replication.
- Think carefully about semantics. DDL syntax that looks simple can be deeply misleading.
- Choose lazy evaluation when validation scope is too broad. Not everything can or should be caught at DDL time.
- Preserve compatibility across versions.Always test your changes with publisher and subscriber on different major versions.
- Understand the historic snapshot.Catalog lookups in output plugins behave differently than in normal backend code.
- Read existing workers before writing new ones.Every signal handler, exit callback, and origin-advance call is there for a reason.
- Focus your optimization effort on streaming mode. That is where the community's energy and the user benefit are greatest.
There is real work to be done, and contributions of all sizes are welcome, from a one-line bug fix to a new major feature.
We hope this post helps you find your entry point.
How to hack the Publisher (Zhijie Hou, Hayato Kuroda)
 Click to view the slides side by side
Click to view the slides side by side Top to bottomClick to view the slides in vertical orientation
Top to bottomClick to view the slides in vertical orientation

























 PostgreSQL Insider
PostgreSQL Insider 
