


Last month I had the opportunity to speak with other Postgres enthusiasts at the PostgreSQL Conference Japan 2021.
I talked about the features and improvements added to PostgreSQL 14, and discussed what is coming next for PostgreSQL, based on what the community has been discussing.
Evolution of PostgreSQL
- Ongoing version upgrades once a year
- Enhanced support for large volume data in recent years
Basically, the first version of PostgreSQL emerged from Postgres 6.0. This was the first open-source release, created using code inherited from the University of California, Berkeley, which had been under development since 1986.
In later years, you can see that a major version was released every year. I have listed some of the recent features that benefited large enterprises - for example, in version 9.0, we introduced streaming replication, and in version 9.1 we introduced asynchronous replication, foreign tables, and unlogged tables.
Similarly, over the next few years, we introduced index-only scan, json data type, updates to foreign data wrappers, materialized views, and jsonb data type. Later, we introduced parallelism, declarative partitioning, and logical replications, as well as a variety of performance enhancements over the years to scale PostgreSQL for large CPUs or machines.
In version 12, we introduced table access methods which enable developers or outside companies to write their own storage methods for accessing tables. My colleague Pankaj Kapoor wrote about this in his post What are table access methods, and what is their importance to PostgreSQL?![]() .
.
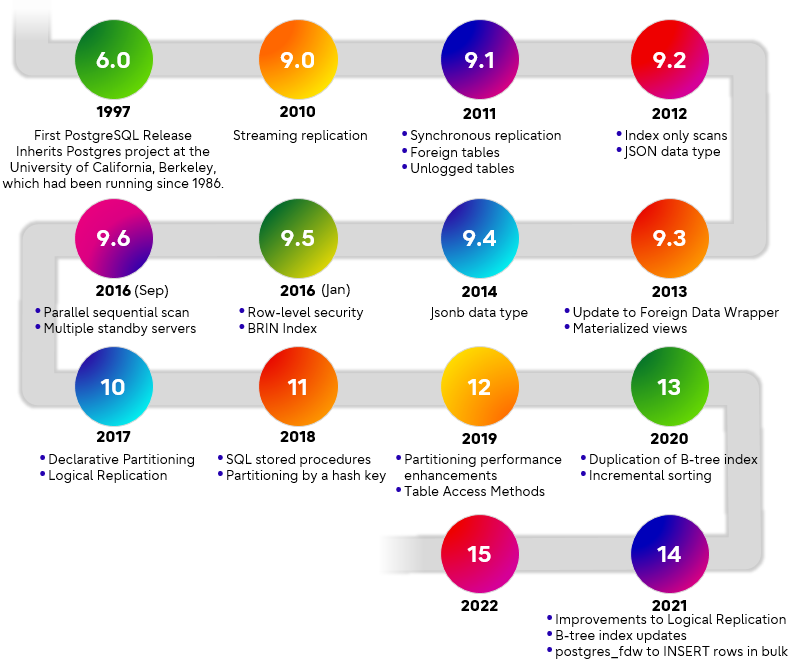
That is a basic summary of the various enhancements done for large enterprises over recent years.
Key features in PostgreSQL 14
Logical Replication improvements
There have been several enhancements to logical replication in PostgreSQL 14. I list them below.
- Support for logical replication of in-progress transactions.
This helps in reducing apply lag for large in-progress transactions but can be improved further. I write about it in detail here
 .
. - Decoding of prepared transactions.
This can help to build a two-phase commit for multi-master solutions and help in reducing apply lag. Note that currently the subscriber-side work is yet to be done but out-of-core solutions can use it for their output plugins. With this feature, users can build a conflict-free replication.
You can read more about it in my colleague Ajin Cherian's blog post Logical decoding of two-phase commits in PostgreSQL 14
. - Performance improvement of logical decoding of transactions containing DDLs.
It has been observed that decoding of a transaction containing truncation of a table with 1,000 partitions would be finished in 1 second, whereas before PostgreSQL 14 it used to take 4-5 minutes.
- Logical replication can now transfer data in binary format.
This is generally faster, if slightly less robust.
- Multiple transactions are now allowed during table synchronization in logical replication.
This brings many benefits, as follows:
- The entire table will no longer need to be copied again if an error happens during the synchronization phase.
- The risk of exceeding the CID limit is avoided.
- The WAL no longer needs to be held until the entire synchronization is finished.
As a result of these changes, logical replication is improved for very large-scale tables where initial synchronization could take a long time.
- The ALTER SUBSCRIPTION statement now makes it easier to add/remove publications, with the addition of ADD PUBLICATION and DROP PUBLICATION options.
- The system view pg_stat_replication_slots was added, reporting replication slot activity.
This helps users to monitor the spill or stream activity and the total bytes decoded via a particular slot.
SQL features
There have also been several useful features enhanced or introduced to PostgreSQL, many of which will help migration from other databases.
- The CREATE FUNCTION and CREATE PROCEDURE statements now support SQL language.
As a result, the function body now conforms to the SQL standard and is portable to other implementations.
Instead of using the PostgreSQL-specific syntax AS $$ … $$, you can now write the SQL statements making up the body unquoted.
CREATE PROCEDURE insert_val (value1 integer, value2 integer)
LANGUAGE SQL
BEGIN ATOMIC
INSERT INTO tbl1 VALUES (value1);
INSERT INTO tbl1 VALUES (value2);
END; - Procedures can have OUT parameters.
Supporting this argument mode will make migration from other databases easier.
- The CREATE TRIGGER syntax has been extended to support OR REPLACE.
This allows pre-existing triggers to be conditionally replaced, and will also make migration easier.
Takamichi Osumi writes about this in his blog post Extending CREATE TRIGGER syntax with OR REPLACE in PostgreSQL code base
. - The ALTER TABLE syntax now supports the options DETACH PARTITION … CONCURRENTLY, as follows:
ALTER TABLE [ IF EXISTS ] name
DETACH PARTITION partition_name [ FINALIZE | CONCURRENTLY ]This allows a partition to be detached from its partitioned table without blocking concurrent queries, by running in two transactions. Because it runs in two transactions, it cannot be used in a transaction block. In case the second transaction is cancelled, or a crash occurs, there's ALTER TABLE… DETACH PARTITION… FINALIZE, which executes the final steps.
- TRUNCATE can operate on foreign tables using the postgres_fdw module.
- Subscripting has been improved.
Extensions and built-in data types can now implement subscripting. For example, jsonb can now use subscripting as follows:
Earlier
SELECT jsonb_column->'key' FROM table;UPDATE table
SET jsonb_column = jsonb_set(jsonb_column, '{"key"}', '"value"');PostgreSQL 14
SELECT jsonb_column['key'] FROM table;UPDATE table
SET jsonb_column['key'] = '"value"'; - Support for multirange data types was added.
These are like range data types, but they allow the specification of multiple, ordered, non-overlapping ranges. All existing range types now also support multirange versions.
As you can see below, before PostgreSQL 14, we could only specify a single date range, whereas now we can specify multiple date ranges using the datemultirange function.
Earlier
SELECT daterange(CURRENT_DATE, CURRENT_DATE + 1);
daterange
-------------------------
[2021-07-27,2021-07-28)PostgreSQL 14
SELECT datemultirange( daterange(CURRENT_DATE , CURRENT_DATE + 2),
daterange(CURRENT_DATE + 5, CURRENT_DATE + 8));
datemultirange
---------------------------------------------------
{[2021-07-27,2021-07-29),[2021-08-01,2021-08-04)} - ECPG now supports a DECLARE STATEMENT construct.
This allows an ECPG SQL identifier to be linked to a specific connection. When the identifier is used by dynamic SQL statements, these are executed by using the associated connection.
This is done via DECLARE … STATEMENT.
EXEC SQL BEGIN DECLARE SECTION;
char dbname[128];
char *dym_sql = "SELECT current_database()";
EXEC SQL END DECLARE SECTION;
int main()
{
EXEC SQL CONNECT TO postgres AS conn1;
EXEC SQL CONNECT TO testdb AS conn2;
EXEC SQL AT conn1 DECLARE stmt STATEMENT;
EXEC SQL PREPARE stmt FROM :dym_sql;
EXEC SQL EXECUTE stmt INTO :dbname;
printf("%s\n", dbname);
EXEC SQL DISCONNECT ALL;
return 0;
}The example above shows how users can declare a simple statement like SELECT current_database() and then define connections to different databases. After that, with DECLARE statement, they can use one of the connections and execute the statement on that connection. This is very useful for applications that want to execute statements on different connections.
Data corruption
PostgreSQL now offers a few tools to provide users with ways to check if their database is corrupted, as well as some small tools to help users correct database corruption where possible. 
- The amcheck module now also provides a function that allows you to check heap pages.
Previously it only allowed you to check B-Tree index pages.
- The command-line utility pg_amcheck was added, to simplify running contrib/amcheck operations on many relations.
It has a wide variety of options for choosing which relations to check and which checks to perform, and it can run checks in parallel.
- The pg_surgery module was added, which allows changes to row visibility information.
This is useful for correcting database corruption, but if misused, it can easily corrupt a database that was not previously corrupted, further corrupt an already-corrupted database, or destroy data.
I want to emphasize that this tool must be used carefully, and only by users who understand what they are doing.
Indexing
- Some GiST indexes can now be built by pre-sorting the data.
Pre-sorting happens automatically and allows for faster index creation and smaller indexes. This is currently supported only for point datatypes.
- BRIN indexes can now record multiple min/max values per range.
- This is useful if there are groups of values in each page range.
- It allows more efficient handling of outlier values.
- It is possible to specify the number of values kept for each page range, either as a single point or an interval boundary.
CREATE TABLE table_name (a int);
CREATE INDEX ON table_name USING brin (a int4_minmax_multi_ops(values_per_range=16));
- BRIN indexes can now use bloom filters.
This allows BRIN indexes to be used effectively with data that is not physically localized in the heap.
- SP-GiST can now use INCLUDE'd columns.
This will allow more index-only-scans for SP-GIST indexes.
- REINDEX can now process all child tables or indexes of a partitioned relation.
- REINDEX can now change the tablespace of the new index.
This is done by specifying a TABLESPACE clause. The --tablespace option was also added to reindexdb to control this.
Extended statistics
The next area where PostgreSQL introduced enhancements is in extended statistics. This will help us obtain better statistics for the various kinds of queries where expressions are used, and will further help generate better query plans for such queries.
- Extended statistics can now be used on expressions.
A simple example may look like this:
CREATE TABLE table_name (a int);
CREATE STATISTICS statistics_name ON mod(a,10), mod(a,20) FROM table_name;
ANALYZE table_name;The collected statistics are useful, for example, to estimate queries with those expressions in WHERE or GROUP BY clauses:
SELECT * FROM table_name WHERE mod(a,10) = 0 AND mod(a,20) = 0;
SELECT 1 FROM table_name GROUP BY mod(a,10), mod(a,20);This feature will allow better query plans when expressions are used in queries.
- The number of places where extended statistics can be used for OR clause estimation has been increased.
Vacuuming
As with previous releases, we have also improved vacuuming in PostgreSQL, with various features in this release.
![]()
- Index vacuuming can be skipped when the number of removable index entries is insignificant.
This will reduce vacuuming time.
- Vacuum operations are now more aggressive if the table is near xid or multixact wraparound.
This is controlled by the vacuum_failsafe_age and vacuum_multixact_failsafe_age parameters. It is expected that this mechanism will almost always trigger within an autovacuum to prevent wraparound, long after the autovacuum began.
- Vacuuming of databases with many relations has been sped up by using existing statistics when possible.
Benchmark results showed a performance improvement of more than three times when there were 20,000 tables and 10 autovacuum workers running.
- Vacuum can eagerly add newly deleted B-tree pages to the free space map so they can be reused.
Previously, vacuum could only place pre-existing deleted pages in the free space map. This improvement will reduce the need to allocate new pages for B-tree index, which will optimize its size.
- Vacuum can reclaim space used by unused trailing heap line pointers.
This avoids line pointer bloat with certain workloads, particularly those involving continual range DELETEs and bulk INSERTs against the same table.
- Vacuum can be more aggressive in removing dead rows during CREATE INDEX CONCURRENTLY and REINDEX CONCURRENTLY operations.
Performance improvements in PostgreSQL 14
This release includes several changes that improve performance, so let's have a look at them.
- The speed of computing MVCC visibility snapshots on systems with many CPUs and high session counts has been improved.
This also improves performance when there are many idle sessions. There is approximately 2x gain for very large number of connections for read-only queries.
- The performance of updates/deletes on partitioned tables when only a few partitions are affected has been improved.
- This also allows updates/deletes on partitioned tables to use execution-time partition pruning.
- For inherited UPDATE/DELETE, instead of generating a separate subplan for each target relation, a single subplan that is just exactly like a SELECT's plan is now generated, then ModifyTable is added on top of that.
- Queries referencing multiple foreign tables can now perform foreign table scans in parallel.
- Currently, the only node type that can be run concurrently is a ForeignScan that is an immediate child of such an Append.
- In cases where such a ForeignScan accesses data on different remote servers, this would run the ForeignScan concurrently and overlap the remote operations to be performed simultaneously. So, it'll improve the performance especially when the operations involve time-consuming ones.
- postgres_fdw supports this type of scan if async_capable is set.
- LZ4 compression can now be used on TOAST data.
- This can be set at the column level, or set as a default via server setting default_toast_compression. The server must be compiled with --with-lz4 to support this feature - the default is still PGLZ.
- LZ4 gets better compression than PGLZ, with less CPU usage. Tests have shown that the speed is improved by more than 2 times, and the size is slightly bigger after using LZ4. I suggest testing this with production data before using any one of the methods.
- Haiying Tang describes how to use this option, and compares its performance with other methods in her blog post What is the new LZ4 TOAST compression in PostgreSQL 14, and how fast is it? .
- B-tree index additions can now remove expired index entries to prevent page splits.
- This is particularly helpful for reducing index bloat on tables whose indexed columns are frequently updated.
- This mechanism attempts to delete whatever duplicates happen to be present on the page when they are suspected to be caused by version churn from successive UPDATEs.
- Pipeline mode has been implemented in libpq.

- This allows multiple queries to be sent and only wait for completion when a specific synchronization message is sent.
- It increases client application complexity, and extra caution is required to prevent client/server deadlocks, but pipeline mode can offer considerable performance improvements in exchange for increased memory usage from leaving state around longer.
- Pipeline mode is most useful when the server is distant, that is, when network latency ping time is high, and when many small operations are being performed in rapid succession.
- Executor method was added to cache results from the inner side of nested loop joins.
- This is useful if only a small percentage of rows is checked on the inner side, and is controlled by the GUC enable_memoize.
- The benefit of using a parameterized nested loop with a result cache increases when there are fewer distinct values being looked up and the number of lookups of each value is large.
- The FDW API and postgres_fdw have been extended to allow batching inserts into foreign tables.
- The idea is that if the FDW supports batching, and batching is requested, then accumulate rows and insert them in batches. Otherwise, use the per-row inserts.
- The batching is usually much more efficient than inserting individual rows, due to high latency for each round-trip to the foreign server.
- Performance of queries having expr IN (const-1, const-2, etc.) clause has been improved.
This is achieved by replacing current linear search with hash table lookup.
- Performance of truncation, drop, or abort of CREATE TABLE operations on small tables during recovery on clusters with a large number of shared buffers has been improved.
This improves performance by more than 100 times in many cases when several small tables (tested with 1,000 relations) are truncated, and where the server is configured with a large value of shared buffers (greater than equal to 100 GB).
- Performance of recovery, standby apply, and vacuum for large updates has been improved.
The performance improvement results from optimizations in the algorithm that compacts pages, which we need to use after large updates.
- Performance of I/O of parallel sequential scans has been improved.
This was done by allocating blocks in groups to parallel workers.
You can check the full list of features added or enhanced in PostgreSQL 14 here![]() .
.
PostgreSQL 15 and beyond
I would like to end by listing the features that I see being discussed in the community, and that can make their way into PostgreSQL 15 or later.
I want to emphasize that the features below are subjective, and there is no guarantee that they will be part of future releases. The list below is based on my personal observations of PostgreSQL Community discussions - neither I nor the community can make any guarantee as to whether these features will be realized. 
- Various improvements in Logical Replication
- Subscriber-side 2PC support
- Publications for schema
- Options/tools to allow conflict resolution
- Replication of sequences
- Row-level filters which will facilitate sharding of data
- Column-level filtering
- Improvement in network bandwidth by not sending empty transactions
- Enable logical replication from standby
- Server-side compression in backup technology
- Improvements in automatic switchover/failover
- Improvements in hash indexes
- Allow unique indexes
- Allow multi-column indexes
- Shared memory stats collector
- More reliable, as we don’t need to communicate over UDP protocol
- Performant, due to lesser reads and writes
- Parallel Writes
- Parallel Inserts
- Parallel Copy From …
- Improvements in Parallel Query
- Asynchronous I/O
This will allow to prefetch data and improve the speed of the system.
- Direct I/O
This will bypass the OS cache and lead to better performance in some cases.
- 2PC via FDW
This is to further advance the PostgreSQL based sharding solution.
- Improvements in vacuum technology by using performance data structure
- Improvements in partitioning technology
- Global Temporary Table
Better management of temporary tables and ease of migration
- Incremental maintenance of materialized views
In conclusion...
There is a constant focus on making PostgreSQL more performant, more suitable for multi-master or distributed workloads, more robust for large read-write workloads, and easier to migrate.
PostgreSQL is constantly gaining popularity and becoming the most popular and default choice to manage data. This is not only evident by DB-Engines ranking![]() , but also by the fact that today many of the Big Tech and cloud companies provide either the support of vanilla PostgreSQL or one of its forks.
, but also by the fact that today many of the Big Tech and cloud companies provide either the support of vanilla PostgreSQL or one of its forks.
Update: Amit Kapila has a newer blog post where he discusses the new and improved features in PostgreSQL 15, and talks about what is being discussed in the PostgreSQL Community for PostgreSQL 16. You can check it here.

