


One of the differences between streaming replication1 and logical replication2 in PostgreSQL is that streaming replication replicates the entire instance, while logical replication allows you to replicate only certain tables and operations.
Before PostgreSQL 15, if a table is published, all its rows and columns are replicated. But with PostgreSQL 15, you can specify row filters and column lists for publications to replicate only the rows and columns that match the specified criteria3. If you are not familiar with these two new features, you can refer to my colleagues' blog posts below.
- Column lists in logical replication publications - an overview of this useful PostgreSQL feature
- Introducing publication row filters
These two new features not only meet the functional needs for users, but also have an impact on performance of logical replication. When using filters, the data is filtered before transmission, which brings some overhead. On the other hand, less data is sent, which saves bandwidth and time spent on data transfer. Also, subscribers spend less time replaying transactions.
Let's see their overall impact on performance with some tests.
Introduction to the performance test
I used two different methods to check how the filter features affect logical replication performance.
Test methods
 I used the following two methods to test different aspects:
I used the following two methods to test different aspects:
- Creating publication and subscription.
Data transfer in logical replication consists of two parts: initial synchronization of table data at the beginning of replication, and incremental synchronization after table synchronization. Row filter and column list work on both of them, so I tested both. In the case of incremental synchronization, synchronous logical replication4 was used, and the execution time of SQL on the publisher side was compared. - Creating publications and then using pg_recvlogical5 to receive data, to compare the execution time of pg_recvlogical.
The first method is closer to real-world scenarios. The second method receives changes in the logical replication slot, which redirects the changes in the specified publication to a file; this will not be affected by anything other than decoding, filtering, and data transfer.
The tests compare replication using row filter/column list against replication not using filters. For row filter, I tested filtering different amounts of rows.
Test steps
For each of the test methods, I followed the steps below:
- Creating publication and subscription
- Initial synchronization
- Create two instances as publisher and subscriber.
- Insert 2 million rows of data on the publisher side, and then create publication.
- Create a subscription on the subscriber side.
- Wait until the table synchronization finishes, and then collect the initial synchronization time.
Start time and end time of table synchronization were obtained from the subscriber log. I ran the test ten times and took the average time.
 Incremental synchronization
Incremental synchronization
- Create two instances as publisher and subscriber. Create the publication and the subscription.
- Set up synchronous logical replication.
- Execute SQL on the publisher side and collect the execution time or tps.
Two scenarios were tested: executing transactions with bulk insert (insert 2 million rows of data in a transaction) and executing transactions with a small number of updates (2 million rows of data in the table, and one row is updated). I used pgbench to collect SQL execution time or tps – the test time was 10 minutes.
- Initial synchronization
- By using pg_recvlogical
- Create an instance as publisher, then create the publication.
- Create a logical replication slot.
- Execute the SQL.
- Use pg_recvlogical to receive data from the publisher and collect the execution time.
Again, two scenarios were tested: executing transactions with bulk insert (insert 2 million rows of data within a transaction) and executing transactions with a small number of updates (update a row in one transaction, a total of 20,000 transactions). I used the time command to record the execution time, ran ten times, and took the average.
Specified GUC parameters
The following are the GUC parameters specified in the performance test to prevent interference from other factors.
shared_buffers = 8GB
checkpoint_timeout = 30min
max_wal_size = 20GB
min_wal_size = 10GB
autovacuum = off
Hardware environment
Two machines were used in the test – one as the publisher and the other as the subscriber (by creating a subscription or using pg_recvlogical). The two machines were in the intranet, and their hardware specs were as follows:
| Publisher | Subscriber | |
| CPU | 16 | 16 |
| Model name | Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz |
Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz |
| Memory | 50 GB | 50 GB |
The network bandwidth between the two machines was about 20.0 Gbits/sec.
Table structure
The table structure in the test was as follows:
postgres=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+-----------------------------+-----------+----------+---------
id | integer | | not null |
kind | integer | | |
key | integer | | |
time | timestamp without time zone | | | now()
item1 | integer | | |
item2 | integer | | |
item3 | integer | | |
item4 | integer | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
For row filter, I filtered data of different proportions according to the value of the kind column. Due to a limitation of the row filter feature, I set the replica identity columns to id and kind.
In the test for column list, only 4 columns were copied - id, kind, key, and time.
Test results
Having described the setup used for the tests, let's have a look at the results.
Row filter
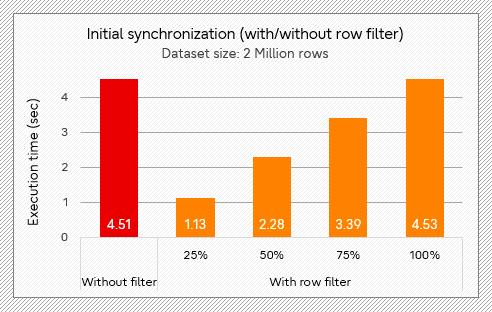
First, I compared the time it took for initial synchronization with different ratios of rows filtered, and without filter. We can see that the proportion of filtered data is basically equal to the proportion of time.
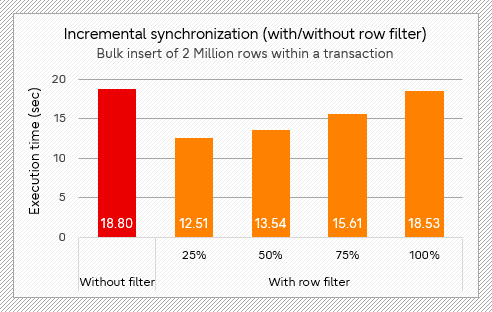
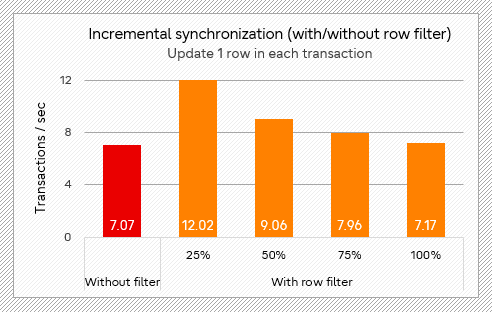
The following two figures are the test results of incremental logical replication. In bulk insert scenario (test 2 below), when a quarter of the data is sent after filtering, the time is reduced by approximately 33% compared with no filter. When executing transactions of a small number of updates (test 3 below), there is also a significant improvement in tps, which is about 70% higher when three-quarters of the data is filtered.
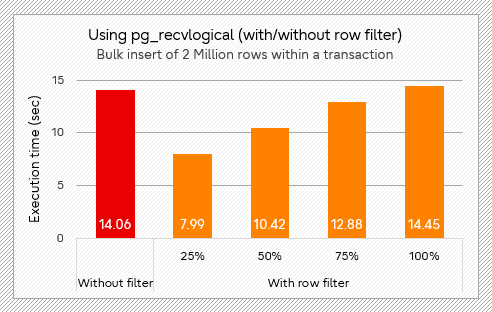
Below are the results using pg_recvlogical. When a quarter of the data is sent, in bulk insert scenario (test 4 below), the time is reduced by about 43% compared with no filter, and in the scenario with transactions of a small number of updates (test 5 below), it is reduced by about 59%. The improvement is more pronounced in the latter scenario.
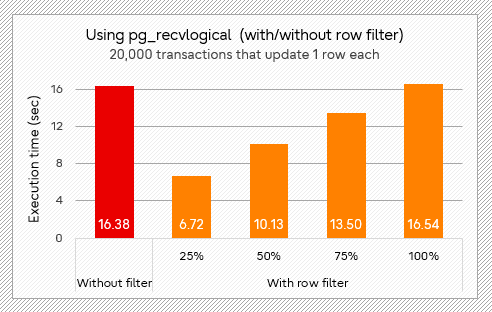
In conclusion, initial synchronization, bulk insert, and a small number of updates can all be significantly improved by using the row filter. Even when the filter does not reduce the data sent, the degradation is not noticeable (less than 3%).
Column list
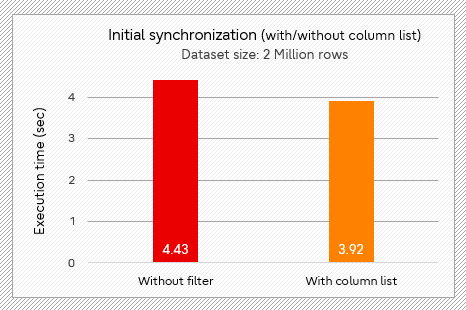
In the initial synchronization scenario, as shown in the figure below, using the column list reduces the time by about 11% compared with no filter.
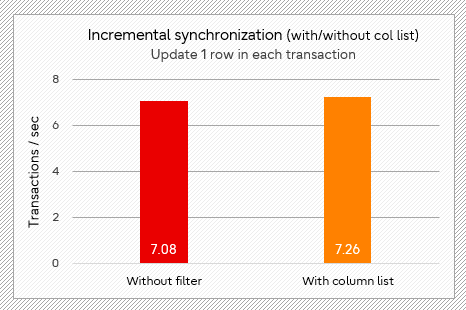
In the test of incremental replication, using column list saves about 14% of the time in the scenario of bulk insert (test 2 below). When transactions with a small number of updates are executed, the tps is increased by 2.5% (test 3 below), and the improvement is not obvious in this case.

The test results of pg_recvlogical are similar to incremental replication, with about 12% improvement in the bulk insert scenario (test 4 below) and 2.7% improvement in small updates scenario (test 5 below).


Overall, the use of column filters improves performance for initial table replications and bulk inserts, but for transactions in which a small number of updates are executed, the performance improvement is not obvious. But if the width of the filtered column is larger (for example, columns to store photos or article content), the improvement may be more obvious.
Effect
From the above test results, we can see some performance improvements brought by row filter and column list in logical replication. By using these 2 features, we can reduce the amount of data sent by the publisher and processed by the subscriber, thus reducing network consumption and CPU overhead. At the same time, it also saves disk space on the subscriber side. If users just need a subset of rows or columns of a table, they can consider using filters to improve performance.
For the future
Row filter and column list in logical replication bring performance improvements. Let us look forward to more new features and performance improvements related to logical replication in future versions of PostgreSQL.
References in this post:
1. https://www.postgresql.org/docs/15/warm-standby.html#STREAMING-REPLICATION
2. https://www.postgresql.org/docs/15/logical-replication.html
3. https://www.postgresql.org/docs/15/release-15.html
4. https://www.postgresql.org/docs/15/warm-standby.html#SYNCHRONOUS-REPLICATION
5. https://www.postgresql.org/docs/15/app-pgrecvlogical.html

