


Before we start
Typically, when using logical replication PUB/SUB, all data changes from the published tables will be replicated to the appropriate subscribers. With the new column lists feature, the user can now limit the replication so that only data from specified columns will be replicated.
Feature overview
 Column lists are optionally specified per table at the time of CREATE PUBLICATION. The column list may be specified after the table name, enclosed in parentheses. Each publication might have zero or more column lists.
Column lists are optionally specified per table at the time of CREATE PUBLICATION. The column list may be specified after the table name, enclosed in parentheses. Each publication might have zero or more column lists.
If a column list is specified, only data from specified columns will be replicated - the list order is not important.
If no column list is specified, all columns of the table are replicated through this publication, including any columns added later. This means a column list which names all columns is not quite the same as having no column list at all. For example, if additional columns are added to the table, then (after a REFRESH PUBLICATION) if there was a column list only those named columns will continue to be replicated.
Column lists have no effect on TRUNCATE commands.
Modified CREATE/ALTER PUBLICATION syntax
Here is a simplified CREATE/ALTER PUBLICATION syntax, highlighting the new column list clause added for PostgreSQL 15:
CREATE PUBLICATION <pub-name> FOR TABLE <table-name> [(column-list)]
ALTER PUBLICATION <pub-name> ADD TABLE <table-name> [(column-list)]
ALTER PUBLICATION <pub-name> SET TABLE <table-name> [(column-list)]
<column-list> ::= <column-list-item> [,<column-list>]
<column-list-item> ::= <column-name>
Column list clause
This clause allows a column list to be specified. Any column list must include the REPLICA IDENTITY columns for UPDATE or DELETE operations to be published. Furthermore, if the table uses REPLICA IDENTITY FULL, specifying a column list is not allowed (it will cause publication errors for UPDATE or DELETE operations). If a publication publishes only INSERT operations, then any column can be specified in the list.
Examples:
CREATE PUBLICATION salary_information FOR TABLE employee (user_id, name, salary);
CREATE PUBLICATION company_address FOR TABLE company (company_id, company_name, address);
Applying column lists
Column lists are applied before the publisher decides to publish the change. The publisher will skip replicating the columns that are not specified in the column list.
Note: A subscription cannot subscribe to multiple publications where the same table was published with different column lists. For example, if we have a publication pub1 that publishes user_id, name and salary columns of the employee table and another publication pub2 that publishes user_id and email_id columns of the employee table, then we cannot have a subscription subscribing to pub1 and pub2 publications, as the column lists are different.
Example 1
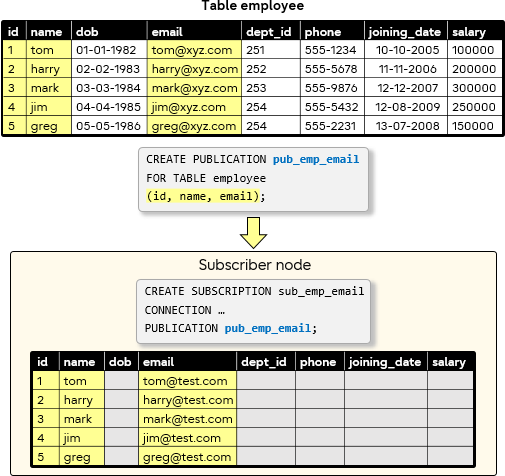
We can see from the above that the columns dob, dept_id, phone, joining_date, and salary were filtered, so data in these columns is not replicated.
Note: While creating the data table in subscriber, the remaining columns (the columns that are not part of the publisher column list) should be created in such a way that NULL values are allowed.
Example 2
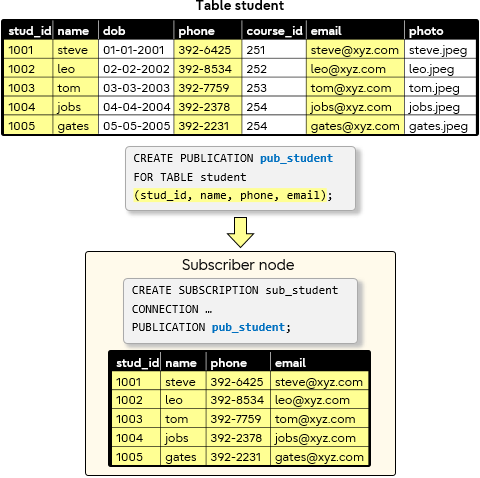
On the subscriber node, create a student table which now only needs a subset of the columns that were on the publisher table student. We can see that the subscriber table does not have the dob, course_id and photo columns.
Initial table synchronization
 When the user elects to use the (default) copy_data = true subscription parameter, then only columns included in the column list are copied to the subscriber.
When the user elects to use the (default) copy_data = true subscription parameter, then only columns included in the column list are copied to the subscriber.
Enhancements to psql commands
As part of this new feature, the PostgreSQL 15 psql commands were also modified to provide useful information about the column lists.
The display table command (\d) now shows the column lists specified for the publication the table is a member of. The display publication command (\dRp+) now shows the column lists specified for the table.
Example
postgres=# CREATE TABLE employee (emp_no INTEGER NOT NULL, name VARCHAR,
postgres(# phone VARCHAR, email VARCHAR,
postgres(# address VARCHAR, dept_no INTEGER,
postgres(# birthday DATE, salary INTEGER);
CREATE TABLE
postgres=# CREATE TABLE department (dept_no INTEGER NOT NULL, dept_name VARCHAR,
postgres(# mgr_no INT, location VARCHAR);
CREATE TABLE
postgres=# CREATE PUBLICATION pub_emp FOR TABLE employee;
CREATE PUBLICATION
-- Publication can be altered to include another table with specified columns.
postgres=# ALTER PUBLICATION pub_emp ADD TABLE department (dept_no, dept_name);
ALTER PUBLICATION
postgres=# CREATE PUBLICATION pub_emp_birthday FOR TABLE employee (emp_no, birthday);
CREATE PUBLICATION
postgres=# CREATE PUBLICATION pub_emp_email FOR TABLE employee (emp_no, email);
CREATE PUBLICATION
postgres=# \d employee
Table "public.employee"
Column | Type | Collation | Nullable | Default
----------+-------------------+-----------+----------+---------
emp_no | integer | | not null |
name | character varying | | |
phone | character varying | | |
email | character varying | | |
address | character varying | | |
dept_no | integer | | |
birthday | date | | |
salary | integer | | |
Publications:
"pub_emp"
"pub_emp_birthday" (emp_no, birthday)
"pub_emp_email" (emp_no, email)
postgres=# \dRp+
Publication pub_emp
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
---------+------------+---------+---------+---------+-----------+----------
vignesh | f | t | t | t | t | f
Tables:
"public.department" (dept_no, dept_name)
"public.employee"
Publication pub_emp_birthday
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
---------+------------+---------+---------+---------+-----------+----------
vignesh | f | t | t | t | t | f
Tables:
"public.employee" (emp_no, birthday)
Publication pub_emp_email
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
---------+------------+---------+---------+---------+-----------+----------
vignesh | f | t | t | t | t | f
Tables:
"public.employee" (emp_no, email)
postgres=#
Effect
 There are several reasons why a user might choose to define logical replication column lists:
There are several reasons why a user might choose to define logical replication column lists:
- To reduce network traffic (increase performance) by replicating only a small subset of a large data table (not replicating images).
Example:CREATE PUBLICATION pub_data_staff_email
FOR TABLE staff (name, email, dept_id, salary); - To provide only the data that is relevant to a subscriber node.
Example:CREATE PUBLICATION pub_data_city_population
FOR TABLE city (name, population); - To act as a form of security by hiding sensitive information (not replicating credit card number).
Example:CREATE PUBLICATION pub_data_customer_investment
FOR TABLE customer_account (name, phone, investment);
For the future
The addition of column lists was a major feature for PostgreSQL 15 logical replication. This feature adds more flexibility to logical replication. The Fujitsu OSS team along with the community will continue to help enhance and add more capabilities to PostgreSQL logical replication.
Where you can find more information

- PostgreSQL documentation page for CREATE PUBLICATION describing the new column lists:
https://www.postgresql.org/docs/15/sql-createpublication.html - PostgreSQL documentation pages describing column lists:
https://www.postgresql.org/docs/devel/logical-replication-col-lists.html - PostgreSQL documentation pages describing replica identity:
https://www.postgresql.org/docs/15/logical-replication-publication.html
https://www.postgresql.org/docs/15/sql-altertable.html#SQL-ALTERTABLE-REPLICA-IDENTITY - PostgreSQL GitHub source code main patch responsible for adding the new column lists feature:
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=923def9a533a7d986acfb524139d8b9e5466d0a5

