



A bare bones RAG setup is a bit like hiring a new broker in a busy marina who doesn’t really know much about boats, then asking them to answer a customer’s question by flicking through a big pile of yacht listings. They might find the right ad and give you something useful, but they’re just as likely to read out specs from an irrelevant fishing trawler, get distracted by glossy photos of a racing catamaran, or miss the perfect Tayana 37 because it’s buried halfway down the stack.
The good news is that PostgreSQL gives us the tools to make this process far more intelligent, so our assistant can skip straight to the most relevant listings and even read them in the right order.
Filtering with facets for smarter retrieval
 One of the easiest improvements to make is filtering by metadata. When we created our embeddings, we had more than just the boat description, we also stored the model, category, hull shape, year, price range, and location alongside it. This information can be stored in a table linked to the vector via a primary ID and used in our retrieval queries. If a buyer asks about a 2020 or newer cruising yacht in Queensland, we can filter out any listings that don’t match those criteria before calculating similarity. That way, our broker never wastes time reading a 1998 racing sloop from Tasmania when the buyer is looking for something completely different.
One of the easiest improvements to make is filtering by metadata. When we created our embeddings, we had more than just the boat description, we also stored the model, category, hull shape, year, price range, and location alongside it. This information can be stored in a table linked to the vector via a primary ID and used in our retrieval queries. If a buyer asks about a 2020 or newer cruising yacht in Queensland, we can filter out any listings that don’t match those criteria before calculating similarity. That way, our broker never wastes time reading a 1998 racing sloop from Tasmania when the buyer is looking for something completely different.
Of course, knowing that we can filter by metadata is one thing, actually deciding which metadata to filter on starts with understanding the buyer’s question. In the same way a good broker listens for key details before opening a single listing, our RAG pipeline needs to pick out the structured attributes hiding inside the query. These are what we call the facets—fields like boat type, category, year range, price, length, and location—and they’re often right there in the customer’s own words.
If someone says, I’m after a 2015 or newer Tayana or similar bluewater cruiser, around 12 metres, under $250k, in Queensland, that’s not just a free-text search. It’s a set of filters waiting to be applied. Some of these facets are easy to spot with simple rules—a year, a price, a length in metres. Others, like bluewater cruiser or similar to Tayana are less direct and may need a language model to interpret and map them to the right metadata fields.
But, once we’ve extracted those facets, we can pass them into our retrieval step. High confidence facets, such as a year or a location explicitly stated, make great hard filters that exclude anything outside the range. Lower confidence facets, such as a style or loosely related make, can be turned into soft boosts in the ranking score, enough to prefer them when they appear, but not enough to rule out other strong matches.
Ranking and ordering for maximum relevance
 By doing this, our broker doesn’t just avoid the wrong boats, they start with a short, on-spec list that’s already tailored to the buyer’s brief. From there, we can focus on ranking, ordering, and merging the results so the LLM sees the most promising candidates first, and in a form that’s easy to understand.
By doing this, our broker doesn’t just avoid the wrong boats, they start with a short, on-spec list that’s already tailored to the buyer’s brief. From there, we can focus on ranking, ordering, and merging the results so the LLM sees the most promising candidates first, and in a form that’s easy to understand.
Once we’ve applied those filters, we still need to decide which of the remaining boats should be shown first. Just because every listing in the pile now meets the basic brief doesn’t mean they’re all equal. In the real world, a broker will instinctively put the newest, best priced, and most appealing options on top of the stack. In our RAG pipeline, we can do the same by introducing combined ranking, blending the similarity score from our vector search with other signals from the metadata. For example, we might give a small bonus to newer listings, a bigger bonus if the make or model exactly matches the request, or even a boost if the asking price sits comfortably within the buyer’s stated range. The similarity score still does the heavy lifting, but these extra nudges ensure the first listings the LLM sees are the ones most likely to satisfy the buyer’s intent.
Order also matters once we’ve decided which listings to show. If we hand the LLM chunks of a boat description in a random sequence, it’s like giving a buyer the engine specifications before they’ve even seen the main photo or layout—all the right information might be there, but it’s harder to piece together into a clear picture. By preserving the original order of sections from each listing, we let the model read the boat’s details in the same logical flow a human would: headline, description, equipment list, then recent upgrades.
From fragments to focused answers
 Sometimes our chunking process will have split a single listing into multiple pieces, perhaps one for the deck layout, another for the interior, and another for navigation gear. If several of these chunks make it into our top results, it often makes sense to merge them back together before passing them to the model. This is like handing the buyer the full printed brochure rather than three loose pages, they see the boat as one complete package, making it easier to understand and evaluate. Merging also cuts down on token usage, leaving more room in the prompt for other promising candidates.
Sometimes our chunking process will have split a single listing into multiple pieces, perhaps one for the deck layout, another for the interior, and another for navigation gear. If several of these chunks make it into our top results, it often makes sense to merge them back together before passing them to the model. This is like handing the buyer the full printed brochure rather than three loose pages, they see the boat as one complete package, making it easier to understand and evaluate. Merging also cuts down on token usage, leaving more room in the prompt for other promising candidates.
By this stage, our broker isn’t just flipping through listings, they’ve already narrowed the search to the right type of boats, put the most promising ones on top, and organized each listing so it reads clearly from start to finish. The final step is telling them exactly how we want the information presented. In RAG, this is where prompt engineering comes in. Just as a broker might be instructed to highlight recent upgrades, point out bluewater capabilities, or compare two similar models side by side, we can guide the LLM to answer in a specific style, focus on certain details, or avoid speculating beyond the provided listings. When combined with well-filtered, well-ordered context, the right prompt can make the difference between a vague, meandering answer and one that’s concise, relevant, and directly tailored to the buyer’s needs.
Building the embedding ingestion pipeline
 Let’s now continue with our practical example of Fujitsu Enterprise Postgres manuals from my previous blog post. We’ve already embedded some manuals in chunks, next we want to identify some facets to store next to our vector embeddings so that we can filter and score them.
Let’s now continue with our practical example of Fujitsu Enterprise Postgres manuals from my previous blog post. We’ve already embedded some manuals in chunks, next we want to identify some facets to store next to our vector embeddings so that we can filter and score them.
This pipeline processes the raw Fujitsu Enterprise Postgres HTML documentation, extracts meaningful content and metadata, generates vector embeddings, and stores everything in a PostgreSQL table designed for hybrid semantic and metadata driven search. Each step builds on the last, ensuring that every piece of content is richly contextualized and ready for improved querying.
The first step is to ensure our table can accommodate the new facets we’ve extracted and to add the necessary indexes so they can be queried efficiently. The fep_manual_chunks table now includes columns for all major metadata fields: document type, product, version, component, operating system, and language, alongside the original text content and its embedding vector. We also add indexes on each facet column to speed up filtering and create an ivfflat index on the embedding column using cosine similarity. This combination allows us to perform fast hybrid searches that first narrow results by metadata and then rank them semantically.
(
id bigserial
primary key,
doc_id text not null,
section text not null,
doc_type text,
product text,
version text,
component text,
os text,
language text,
updated_at date default CURRENT_DATE,
content text not null,
embedding vector(1536)
);
alter table fep_manual_chunks
owner to garyevans;
create index fep_manual_chunks_doc_type_idx
on fep_manual_chunks (doc_type);
create index fep_manual_chunks_version_idx
on fep_manual_chunks (version);
create index fep_manual_chunks_component_idx
on fep_manual_chunks (component);
create index fep_manual_chunks_os_idx
on fep_manual_chunks (os);
create index fep_manual_chunks_language_idx
on fep_manual_chunks (language);
create index fep_manual_chunks_updated_at_idx
on fep_manual_chunks (updated_at);
create index fep_manual_chunks_embedding_idx
on fep_manual_chunks using ivfflat (embedding vector_cosine_ops);
The process begins by iterating over a list of HTML files like in our previous article, parsing each one and collecting its extracted rows. The rows include both the text that will later be embedded and the associated facets that describe it. To avoid excessive transaction sizes, the script accumulates these rows in memory and only inserts them into the database in batches of a thousand. This keeps database operations efficient, reduces the chance of transaction contention, and provides progress updates as the ingestion proceeds. Any errors in processing a single file are caught and reported without halting the run, ensuring the pipeline is resilient to imperfect inputs.
![]() You can download the Python script in this example here.
You can download the Python script in this example here.
batch_rows: List[Tuple] = []
for idx, path in enumerate(html_files, 1):
try:
rows = process_html_file(path, version, os_facet)
batch_rows.extend(rows)
# Insert in DB-sized batches to avoid giant transactions
if len(batch_rows) >= 1000:
insert_rows(batch_rows)
total_rows += len(batch_rows)
print(f"[{idx}/{len(html_files)}] Inserted {len(batch_rows)} rows (cumulative {total_rows})")
batch_rows.clear()
except Exception as e:
print(f"Error processing {path}: {e}", file=sys.stderr)
Once the content is parsed, the next task is to extract structured facets, metadata fields that will make the stored content more discoverable and filterable. The parsing uses BeautifulSoup, a widely used Python library for navigating HTML, to locate and cleanly extract specific elements from the document. These facets include attributes such as product version, category, operating system, and any other relevant metadata. The product version and OS are passed into the parser explicitly, which constrains the process to only handle one version/OS combination at a time. This ensures dataset consistency and avoids mixing content from different product builds. Importantly, these facets are stored in the same table as the text and embeddings, enabling queries that combine precise filtering with semantic ranking without the need for joins.
with open(path, "rb") as file:
soup = BeautifulSoup(file, features:"html.parser")
title = extract_title(soup)
lang = detect_language(soup)
section_number = infer_section_from_title(title)
doc_type = infer_doc_type_from_title(title)
breadcrumbs = extract_breadcrumbs(soup)
# Use breadcrumbs + title to infer component
component = infer_component(breadcrumbs + " " + title)
# Use provided OS facet instead of inferring it
os_name = os_facet
updated_at = infer_updated_date(soup)
# Build a stable doc_id per manual/guide
doc_id = build_doc_id(title, version, lang)
# Extract logical section blocks in order
blocks = extract_section_blocks(soup)
One of these facets is the document type. A helper function inspects each document’s title, normalizes it to lowercase, and searches for keywords such as install, administration, release notes, or tutorial. Each match maps to a standard label, ensuring consistent tagging across the dataset even if the original titles vary. If no match is found, the type is left unspecified. This simple rule-based approach is fast and transparent, but could later be replaced or augmented with a machine learning classifier for greater flexibility and accuracy.
tl = title.lower()
if "install" in tl or "installation" in tl or "setup" in tl:
return "install"
if "administration" in tl or "operations" in tl or "admin" in tl:
return "admin"
if "release notes" in tl or "release-notes" in tl:
return "release-notes"
if "application development" in tl or "development guide" in tl or "tutorial" in tl or "guide" in tl:
return "tutorial"
return None
Another facet is the component the document relates to, such as replication, backup, security, or monitoring. A dictionary maps each component to a set of representative keywords, and the infer_component function checks whether any of these keywords appear in the text. If a match is found, the corresponding component label is returned. This provides an easy way to classify documentation into functional areas, with minimal processing cost, while still leaving room for future enhancement with more sophisticated NLP techniques.
"replication": ["replication", "logical", "physical", "wal", "publisher", "subscriber", "slot"],
"backup": ["backup", "restore", "recovery", "barman", "base backup"],
"security": ["tls", "ssl", "audit", "row security", "rls", "encryption"],
"knowledge management": ["vector", "embedding", "semantic", "pgvector", "rag", "ai"],
"monitoring": ["monitoring", "metrics", "prometheus", "exporter"],
"administration": ["WebAdmin", "admin", "user", "role", "group", "permission", "authentication", "authorization"],
"application development": ["application", "development", "guide", "tutorial", "guideline", "tutorial", "guide", "sql", "function", "api programming"],
"dev": ["application development", "literal", "syntax", "sql", "function", "api", "programming"]
}
def infer_component(text: str) -> Optional[str]:
tl = text.lower()
for comp, kws in COMPONENT_KEYWORDS.items():
if any(k in tl for k in kws):
return comp
return None
To uniquely identify each document, the pipeline generates a stable doc_id based on its title, version, and language. Leading product and version words are stripped using regular expressions so that the ID focuses on the actual manual section name. The result is slugified for consistency, and the version and language are appended, producing identifiers like app_development_guide_v17_en. Alongside this, the script also extracts breadcrumb trails from the HTML, capturing the document’s position in the documentation hierarchy for added navigational context.
"""
Create a stable doc_id per manual (not per page).
Example: "Application Development Guide" + v17 + en -> "app_development_guide_v17_en"
"""
# Strip the leading product/version words to focus on the guide name
t = re.sub(r"^enterprise\s+postgres\s+\d+(\s+sp\d+)?\s*", "", title, flags=re.IGNORECASE)
t = re.sub(r"^fujitsu\s+enterprise\s+postgres\s+\d+(\s+sp\d+)?\s*", "", t, flags=re.IGNORECASE)
base = slugify(t)
ver = version or "vxx"
return f"{base}_{ver}_{lang}"
def extract_breadcrumbs(soup: BeautifulSoup) -> str:
bc = soup.select_one(".breadcrumbslist")
return bc.get_text(" ", strip=True) if bc else ""
The actual text content to be embedded is segmented using the extract_section_blocks function. This scans for <h2>, <h3>, and <h4> headings and groups them with their following body content, filtering out irrelevant elements such as navigation menus, scripts, and styles. If no headings are found, the entire body text is taken as a single block. This block-level segmentation allows the system to embed smaller, thematically consistent chunks rather than entire documents, improving precision in semantic search.
blocks: List[Tuple[str, str]] = []
# Primary: H2, H3, H4 sections and their following sibling .body
for h in soup.find_all(["h2", "h3", "h4"]):
heading = h.get_text(" ", strip=True)
# Accumulate sibling text until next heading of same/higher level
body_parts = []
for sib in h.find_all_next():
if sib.name in ["h2", "h3", "h4"] and sib is not h:
break
# Only pick within a reasonable container before next header/footer
if sib.name in ["div", "p", "pre", "ul", "ol", "table", "dl"]:
# Skip nav & footer
if sib.get("class") and any(c in ("top_header", "header_footer") for c in sib.get("class", [])):
continue
# Avoid scripts/styles
if sib.name in ["script", "style"]:
continue
body_parts.append(sib.get_text(" ", strip=True))
body = "\n".join([p for p in body_parts if p])
if heading or body:
blocks.append((heading, body))
# Fallback: if no headings found, use entire body text
if not blocks:
body = soup.get_text(" ", strip=True)
if body:
blocks = [("Page", body)]
return blocks
Each block is then split further into smaller, overlapping chunks using the chunk_text function. This ensures each embedding remains within the model’s token limit while preserving enough surrounding context to be meaningful in isolation. An overlap is maintained between chunks so that information spanning boundaries isn’t lost, and the heading is included at the start of each chunk for grounding in downstream RAG (Retrieval-Augmented Generation) workflows.
full = (heading.strip() + "\n" + text.strip()).strip()
if not full:
return []
chunks = []
start = 0
while start < len(full):
end = min(len(full), start + target_chars)
chunk = full[start:end].strip()
if start > 0 and heading:
# Re-add a short heading context for downstream grounding
chunk = f"{heading}\n{chunk}"
if chunk:
chunks.append(chunk)
if end == len(full):
break
start = max(end - overlap, start + 1)
return chunks
The embed_texts function takes these chunks and converts them into high-dimensional embeddings using the chosen model. Chunks are processed in batches to keep API calls efficient and predictable, with the resulting vectors stored in the same order as the input text for direct mapping back to their source chunks and facets. The function is model-agnostic, so the embedding provider can be swapped out or upgraded without changing the surrounding pipeline.
vectors: List[List[float]] = []
for i in range(0, len(texts), EMBED_BATCH_SIZE):
batch = texts[i:i+EMBED_BATCH_SIZE]
resp = client.embeddings.create(
model=EMBED_MODEL,
input=batch
)
vectors.extend([d.embedding for d in resp.data])
return vectors
Finally, all the data: chunk content, embeddings, and the full set of facets is inserted into the fep_manual_chunks table. The insert_rows function uses PostgreSQL’s psycopg2 library with execute_values for high-performance batch insertion, explicitly casting embeddings to the vector type so they’re ready for similarity search. By committing after each batch, the process keeps transactions manageable and avoids locking large portions of the table.
INSERT INTO fep_manual_chunks
(doc_id, section, doc_type, product, version, component, os, language, updated_at, content, embedding)
VALUES %s
"""
def insert_rows(rows: List[Tuple[str, int, Optional[str], str, Optional[str], Optional[str], Optional[str], str, dt.date, str, str]]):
# We need to annotate the embedding param as ::vector.execute_values doesn't
# let us place casts per-row easily, so we embed the cast in the template.
with psycopg2.connect(**PG_CONN_INFO) as conn:
with conn.cursor() as cur:
execute_values(
cur,
INSERT_SQL,
rows,
template="(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s::vector)"
)
conn.commit()
The result is a fully populated database where each chunk of text is semantically indexed and richly described with structured metadata. This unified design enables hybrid search by the ability to filter by exact criteria such as version, OS, or component, and then rank the results by their semantic closeness to a query. Every stage from HTML parsing to embedding generation is modular, making it easy to refine or replace components without re-architecting the system.
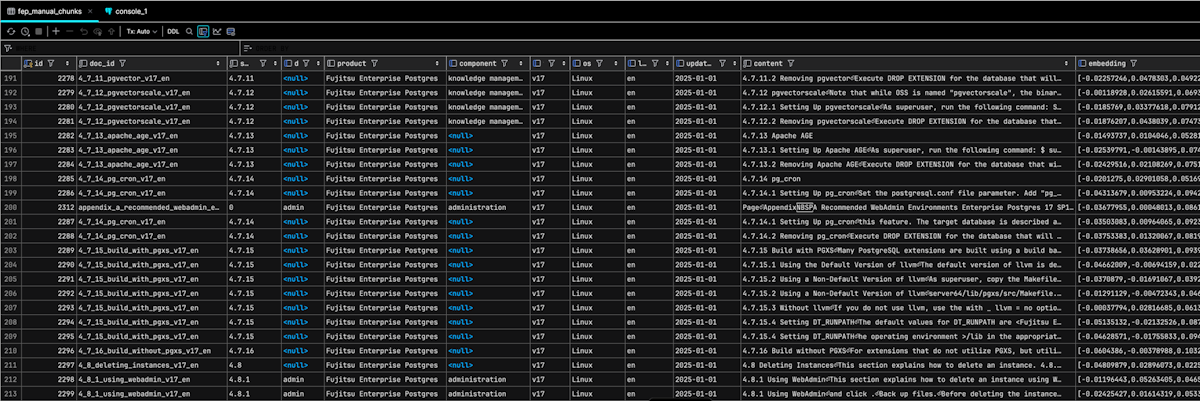
With the pipeline complete, the populated fep_manual_chunks table now contains a fully processed, searchable representation of the documentation. Each row represents a single chunk of text, enriched with its associated facets and a precomputed vector embedding. The doc_id column provides a stable identifier linking the chunk to its parent document, while fields like product, version, component, os, and language make it possible to precisely filter results before performing semantic search. The content column holds the original text for reference or display, and the embedding column stores its high-dimensional vector representation in PostgreSQL’s vector type, ready for similarity queries.
In this snapshot we can see examples of chunks tagged with components such as knowledge management and administration, as well as others where the component is currently NULL—these could be candidates for further facet inference or future machine learning classification. The uniform version and os values reflect the pipeline’s constraint of processing one version x OS combination at a time, ensuring consistency in the dataset. This structure allows for hybrid search queries that can, for example, return only knowledge management chunks for version 17 running on Linux, ranked by how semantically close they are to a user’s query.
What’s most important is that every chunk in this table is now both machine-understandable (via embeddings) and human-filterable (via facets), making it a powerful foundation for documentation search, question answering, and other RAG applications.
In the next post
 In my next blog post, we’ll explore the pipeline for accessing these stored facets and using them to control and refine search results.
In my next blog post, we’ll explore the pipeline for accessing these stored facets and using them to control and refine search results.
We’ll also look at how prompt design influences retrieval strength, showing how the right wording can fully leverage both the metadata filters and the semantic matching capabilities we’ve just built. From there, we’ll begin our deep dive into Agents and agentized RAG, where these foundations open the door to far more autonomous and adaptive search workflows.
Other blog posts in this series
- Why Enterprise AI starts with the database - Not the data swamp
- Understanding similarity vs distance in PostgreSQL vector search
- What is usually embedded in vector search: Sentences, words, or tokens?
- How to store and query embeddings in PostgreSQL without losing your mind
- Embedding content in PostgreSQL using Python: Combining markup chunking and token-aware chunking
- From embeddings to answers: How to use vector embeddings in a RAG pipeline with PostgreSQL and an LLM



 PostgreSQL Insider
PostgreSQL Insider 
