


Before we start
Logical replication is a method of selective data replication. While physical replication copies whole clusters and accepts read-only queries on the standby if required1, logical replication gives more fine-grained and flexible control over data replication. Some of the capabilities available in logical replication are:
- Selection of target tables and operations
- Direct writes on the subscriber
- Complex topology between publications and subscriptions
In logical replication, data is applied on the subscriber by subscription worker process, which operates in a similar way to conduct DML operations on the node. So, if new incoming data violates any constraints on the subscriber, the replication stops with error.
This is referred to as conflict2, and requires manual intervention from the user so that it can proceed.
So, what changes in PostgreSQL 15?
In PostgreSQL 15, the PostgreSQL community is introducing improvements and new features useful to tackle logical replication conflicts. I’ll describe these improvements and how you can apply them to handle conflicts.
In this post, the resolution is achieved by skipping the transaction that conflicts with existing data. Regarding the auto-disabling feature (disable_on_error option) described in this post, I also worked as one of the developers in the community. The figure below illustrates how a conflict may happen during apply.
Disclaimer: In this post I’ve used the development version of PostgreSQL, and the community can either decide to change its design or completely revert those.
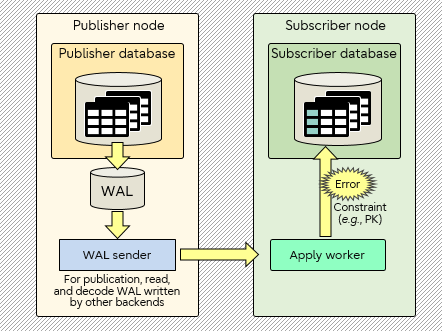
Improvements to logical replication and new features
The community has been working really hard to make sure that Postgres provides a reliable, efficient, and easy measure in terms of logical replication. Part of this effort are the commit of the features and improvements below:
- New system view pg_stat_subscription_stats3 for subscription statistics
Each record of this view refers to a subscription. In this view, we have implemented two types of failure counters: one for failure in initial table synchronization, and another for failure in application of changes.
- New subscription option disable_on_error4
When a conflict occurs, the logical replication worker gets stuck in an error loop by default. The reason is that when the worker fails to apply a change, it exits with an error, restarts, and tries to apply the same change repeatedly in the background. But with this new option, the subscription worker can break the loop by disabling the subscription automatically on error. After that, users can choose what to do next. Failures during initial table synchronization also disable the subscription. The default value is false and setting it to false repeats the same error on conflict.
- Extended error context information of subscription worker error
The error context message now includes 2 new pieces of information conditionally5:
- Finish LSN. In general, LSN is a pointer to a location in the WAL. Here, finish LSN will indicate commit_lsn for committed transactions, and prepare_lsn for prepared transactions.
- Replication origin name6. This will contain the name of replication origin that keeps track of replication progress. For logical replication, each corresponding replication origin is created automatically, along with the subscription definition.
Both pieces of information above will be useful when users need to use the pg_replication_origin_advance function7.
Resolving conflicts by skipping a failing transaction
We have checked each enhancement for this theme. So, in this section, I’ll emulate one conflict scenario. Keep in mind that skipping a transaction by calling pg_replication_origin_advance is just one of the resolutions that users can choose, users can also change data or permissions on the subscriber to solve the conflict.
1 On the publisher side, create a table and a publication.
postgres=# CREATE TABLE tab (id integer);
CREATE TABLE
postgres=# INSERT INTO tab VALUES (5);
INSERT 0 1
postgres=# CREATE PUBLICATION mypub FOR TABLE tab;
CREATE PUBLICATION
We now have one record for initial table synchronization.
2 On the subscriber side, create a table with a unique constraint and a subscription.
postgres=# CREATE TABLE tab (id integer UNIQUE);
CREATE TABLE
postgres=# CREATE SUBSCRIPTION mysub CONNECTION '…' PUBLICATION mypub WITH (disable_on_error = true);
NOTICE: created replication slot "mysub" on publisher
CREATE SUBSCRIPTION
We have now created a subscription with the disable_on_error option enabled. At the same time, this definition causes the initial table synchronization in the background, which will succeed without any issues.
3 On the publisher side, execute three transactions in succession after the table synchronization.
postgres=# BEGIN; -- Txn1
BEGIN
postgres=*# INSERT INTO tab VALUES (1);
INSERT 0 1
postgres=*# COMMIT;
COMMIT
postgres=# BEGIN; -- Txn2
BEGIN
postgres=*# INSERT INTO tab VALUES (generate_series(2, 4));
INSERT 0 3
postgres=*# INSERT INTO tab VALUES (5);
INSERT 0 1
postgres=*# INSERT INTO tab VALUES (generate_series(6, 8));
INSERT 0 3
postgres=*# COMMIT;
COMMIT
postgres=# BEGIN; -- Txn3
BEGIN
postgres=*# INSERT INTO tab VALUES (9);
INSERT 0 1
postgres=*# COMMIT;
COMMIT
postgres=# SELECT * FROM tab;
id
----
5
1
2
3
4
5
6
7
8
9
(10 rows)
Txn1 can be replayed successfully. But the second statement of Txn2 (highlighted in blue above) includes a duplicated value same as the table synchronization (also highlighted in blue in the first command section). On the subscriber, this violates the unique constraint on the table. Therefore, it will cause a conflict and disable the subscription. As a result, the subscription will stop here. Txn3 won’t be replayed until the conflict is addressed, as per the steps below.
4 On the subscriber side, check the current replication status.
postgres=# SELECT * FROM pg_stat_subscription_stats;
subid | subname | apply_error_count | sync_error_count | stats_reset
-------+---------+-------------------+------------------+-------------
16389 | mysub | 1 | 0 |
(1 row)
postgres=# SELECT oid, subname, subenabled, subdisableonerr FROM pg_subscription;
oid | subname | subenabled | subdisableonerr
-------+---------+------------+-----------------
16389 | mysub | f | t
(1 row)
postgres=# SELECT * FROM tab;
id
----
5
1
(2 rows)
Before skipping a transaction, we’ll have a look at the current status.
There was no failure during initial table synchronization, but there was one during apply phase. That is what pg_stat_subscription_stats shows so far. Furthermore, since we created the subscription with the disable_on_error option set to true, the subscription mysub has been disabled due to the failure. The table tab has the data replicated up to Txn1, which we have successfully replayed.
5 On the subscriber side, check the error message of this conflict and the log message of the disable_on_error option.
ERROR: duplicate key value violates unique constraint "tab_id_key"
DETAIL: Key (id)=(5) already exists.
CONTEXT: processing remote data for replication origin "pg_16389" during "INSERT"
for replication target relation "public.tab" in transaction 730 finished at 0/1566D10
LOG: logical replication subscription "mysub" has been disabled due to an error
Above we can see the replication origin name and the LSN that indicates commit_lsn. I’ll utilize those to skip Txn2 as below.
6 On the subscriber side, execute pg_replication_origin_advance and then enable the subscription.
postgres=# SELECT pg_replication_origin_advance('pg_16389', '0/1566D11'::pg_lsn);
pg_replication_origin_advance
-------------------------------
(1 row)
postgres=# ALTER SUBSCRIPTION mysub ENABLE;
ALTER SUBSCRIPTION
postgres=# SELECT * FROM tab;
id
----
5
1
9
(3 rows)
After making the origin advance, I enabled the subscription to re-activate it - immediately, we can see the replicated data for Txn3.
Here, note that some other data irrelevant to the direct cause of the conflict in Txn2, regardless of the timing within the same transaction (remember, we performed other inserts in Txn2, highlighted in red), was not replicated - the whole transaction Txn2 was skipped.
The sequence of events here is as follows:
- We used pg_replication_origin_advance and enabled the subscription.
- Enabling the subscription launched the apply worker and it sent the LSN passed via pg_replication_origin_advance to the walsender process on the publisher.
- This walsender process evaluated whether transaction Txn2 should be sent or skipped at decoding commit, by comparing the related LSNs.
- The walsender concluded that transaction Txn2 should be skipped.
Lastly, I emphasize we must pay attention to pass an appropriate LSN to pg_replication_origin_advance. Although the possibility is becoming quite low because of the new community’s improvements described in this blog, it can easily skip other transactions unrelated to the conflict if it’s misused.
What can go wrong if I specify the wrong parameters?
 For reference, we provide an example of what would happen if we use pg_replication_origin_advance incorrectly.
For reference, we provide an example of what would happen if we use pg_replication_origin_advance incorrectly.
Below, I re-executed the above scenario with one more transaction Txn4 to insert 10 after Txn3. Then, as the argument of pg_replication_origin_advance, I set a LSN bigger than that of Txn3’s commit record but smaller than that of Txn4’s commit record (retrieved by pg_waldump8). After I enabled the subscription, I got the replicated data without the value of Txn3.
Result on the subscriber side of using pg_replication_origin_advance incorrectly is as follows.
postgres=# SELECT * FROM tab;
id
----
5
1
10
(3 rows)
As shown above, we can never be too careful when manually intervening in the replication to solve conflicts.
On this point, the community has already introduced a different feature (ALTER SUBSCRIPTION SKIP) separately.
This feature is one step ahead of pg_replication_origin_advance in the aspect of handling
logical replication conflicts. Please have a look at my next post that describes the detail.
Wrapping up
As logical replication becomes more widely adopted in enterprises, the need for handling practical problems like conflicts becomes ever more important. For this reason, the improvements added to PostgreSQL are essential.
The PostgreSQL community has been hardening the database, and in this blog post I have described an easy way to handle logical replication conflicts. Still, we have to be careful to provide the correct information for the tool being used, in this case pg_replication_origin_advance.
If you would like to learn more
If you would like to read more about logical replication and its mechanics in PostgreSQL, I wrote the blog post How to gain insight into the pg_stat_replication_slots view by examining logical replication. And my colleague Ajin Cherian wrote a blog post on Logical decoding of two-phase commits in PostgreSQL 14 in case you would like to learn more about logical decoding and how PostgreSQL performs it for two-phase commits.
References in this post:
1. https://www.postgresql.org/docs/devel/hot-standby.html
2. https://www.postgresql.org/docs/devel/logical-replication-conflicts.html
3. https://www.postgresql.org/docs/devel/monitoring-stats.html#id-1.6.15.7.13.2
4. https://www.postgresql.org/docs/devel/sql-createsubscription.html
5. https://www.postgresql.org/docs/devel/error-message-reporting.html
6. https://www.postgresql.org/docs/current/replication-origins.html
7. https://www.postgresql.org/docs/devel/functions-admin.html#id-1.5.8.33.8.5.2.2.20.1.1.1

