


Background
Logical replication of specific tables or all tables in the database from publisher to subscriber is supported since PostgreSQL 10. If users want to publish tables present in one schema or multiple schemas, they have to prepare the table list manually by querying the database, and then create a publication by using the manually prepared list.
When there are only a few tables in the schema, then preparing the list is quick and easy, but if there are hundreds or thousands of tables, then this will be a tedious task.
To overcome this problem, the upcoming PostgreSQL 15 will add the option TABLES IN SCHEMA, which will allow one or more schemas to be specified, whose tables are selected by the publisher for sending data to the subscriber.
Note: In this post, I will refer to this new feature that enables logical replication of tables in schema as schema publication.
Feature overview
The figure below illustrates the working of logical replication of schema publication:
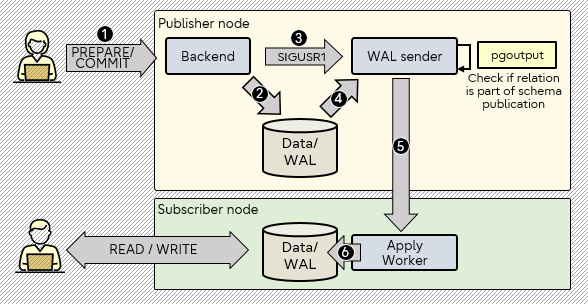
Let's go step by step through the stages in the diagram above:
1 User performs various DML operations on tables and executes prepare/commit.
2 The backend process will generate data/WAL for the operations performed by the user.
3 The backend sends the SIGUSR1 signal to the WAL sender process to notify that WAL records are available for processing.
4 The walsender process starts logical decoding of the WAL records - the pgoutput plugin transforms the changes read from the WAL.
5 The pgoutput plugin checks if the data is part of the schema publication or not. If it is, then data is continuously transferred to the Apply Worker using the streaming replication protocol.
6 The Apply Worker maps the data to local tables and applies the individual changes as they are received, in correct transactional order.
You can view further details of the implementation in the PostgreSQL git repository.
Changes in the syntax
The new syntax allows including the tables in the specified schemas when creating or altering the publication.
or
In addition to specifying schemas, the new syntax also allows specifying individual tables when creating or altering publication.
or
Note that adding schemas to a publication that is already subscribed to will require an ALTER SUBSCRIPTION … REFRESH PUBLICATION action on the subscribing side in order to become effective.
New system table pg_publication_namespace
A new system table pg_publication_namespace will be added, to maintain the schemas that the user has specified for publication.
Users can use pg_publication_namespace and pg_publication to get the schema mapping with the publication, as in the example below.
CREATE PUBLICATION
postgres=# SELECT pubname, pnnspid::regnamespace
postgres-# FROM pg_publication_namespace pn, pg_publication p
postgres-# WHERE pn.pnpubid = p.oid;
pubname | pnnspid
---------+---------
pub1 | sch1
pub1 | sch2
(2 rows)
Changes to pgoutput
The pgoutput plugin was modified to check if the relation is part of schema publication and publish the changes to the subscriber.
Describe publication
The \d family of commands was updated to display schema publications, and the \dRp+ variant will
now display the schemas associated with the publication.
CREATE PUBLICATION
postgres=# \dRp+ pub1
Publication pub1
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
------+------------+---------+---------+---------+-----------+----------
Dba | f | t | t | t | t | f
Tables from schemas:
"sch1"
"sch2"
Changes to pg_dump
The pg_dump client tool has been updated to identify if the publication was created to publish tables in schema and dumps the ddl for the publication including the TABLES IN SCHEMA option.
Sample of the DDL generated by pg_dump:
-- Name: pub1; Type: PUBLICATION; Schema: -; Owner: dba
--
CREATE PUBLICATION pub1 WITH (publish = 'insert, update, delete, truncate');
ALTER PUBLICATION pub1 OWNER TO dba;
--
-- Name: pub1 sch1; Type: PUBLICATION TABLES IN SCHEMA; Schema: sch1; Owner: dba
--
ALTER PUBLICATION pub1 ADD TABLES IN SCHEMA sch1;
--
-- Name: pub1 sch2; Type: PUBLICATION TABLES IN SCHEMA; Schema: sch2; Owner: dba
--
ALTER PUBLICATION pub1 ADD TABLES IN SCHEMA sch2;
Changes to psql
The psql client tool has been updated to support tab completion of the TABLES IN SCHEMA option.
How to publish TABLES IN SCHEMA data?
Here are the steps to use the new TABLES IN SCHEMA option.
1Create a few schemas and tables in the publisher and the subscriber:
CREATE SCHEMA
postgres=# CREATE TABLE sch1.tbl1 (col1 int);
CREATE TABLE
postgres=# CREATE TABLE sch1.tbl2 (col1 int);
CREATE TABLE
postgres=# CREATE SCHEMA sch2;
CREATE SCHEMA
postgres=# CREATE TABLE sch2.tbl3 (col1 int);
CREATE TABLE
postgres=# CREATE TABLE sch2.tbl4 (col1 int);
CREATE TABLE
2Create the publication in the publisher:
CREATE PUBLICATION
3Create the subscription in the subscriber by specifying the publisher host and the publisher port 6666:
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTION
4Insert some data into the publisher:
INSERT 0 1
postgres=# INSERT INTO sch1.tbl2 VALUES(12);
INSERT 0 1
postgres=# INSERT INTO sch2.tbl3 VALUES(23);
INSERT 0 1
postgres=# INSERT INTO sch2.tbl4 VALUES(24);
INSERT 0 1
5Check that the data published by the publisher is logically replicated to the subscriber:
col1
----
11
(1 rows)
postgres=# SELECT * FROM sch1.tbl2;
col1
----
12
(1 rows)
postgres=# SELECT * FROM sch2.tbl3;
col1
----
23
(1 rows)
postgres=# SELECT * FROM sch2.tbl4;
col1
----
24
(1 rows)
For the future
With the changes that went into this feature in PostgreSQL 15, we now have the infrastructure that allows decoding of tables present in a schema.
The next step is to implement the support for skipping few tables present in the schema, in the later versions of PostgreSQL.
If you would like to learn more
If you would like to learn more about the pg_stat_replication_slots view, my colleague Takamichi Osumi wrote a blog post on it - How to gain insight into the pg_stat_replication_slots view by examining logical replication.
Based on community feedback we have changed "ALL TABLES IN SCHEMA" syntax to "TABLES IN SCHEMA".
Updated November 9,2022

