



Unlocking the secrets of WAL: My PGConf India 2025 talk
Below, you'll find the slides from my presentation at PGConf India 2025.
 Click to view the slides side by side
Click to view the slides side by side Top to bottomClick to view the slides in vertical orientation
Top to bottomClick to view the slides in vertical orientation


What is WAL
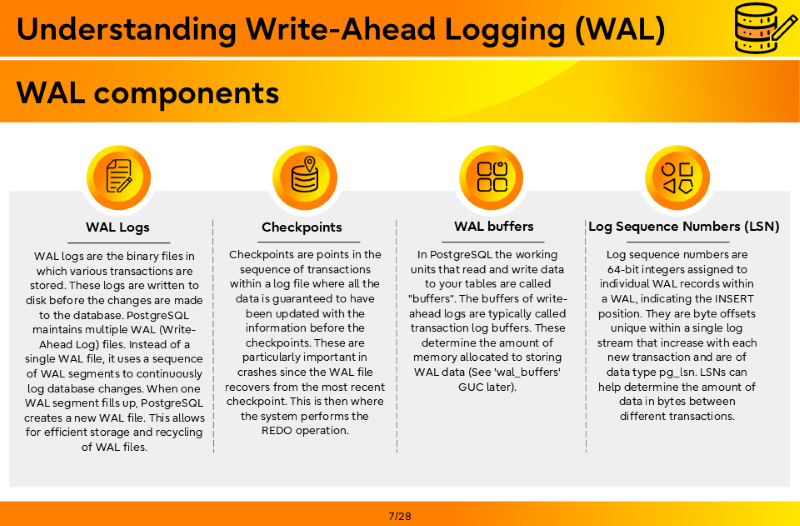
- The WAL (Write-ahead logs) is a sequential record of all changes made to a database
- WAL files are stored in the directory pg_wal under the data directory
- Whenever a transaction modifies data in PostgreSQL, the changes are first written to the WAL file before they are applied to the actual on-disk table data files
- This process is known as write-ahead logging
- The WAL in PostgreSQL is stored in a set of log files called WAL segments (16MB by default)
- Once a segment is filled, it is archived, depending on the database configuration
- WAL segments preceding the one containing the redo record are no longer needed and can be recycled or removed
- The WAL segments can be replayed during crash recovery or used for replication purposes
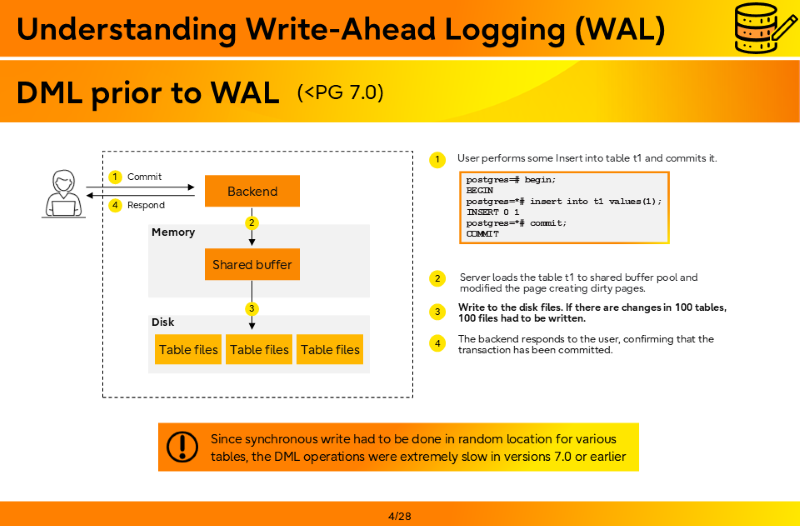
DML prior to WAL (<Postgres 7.0)
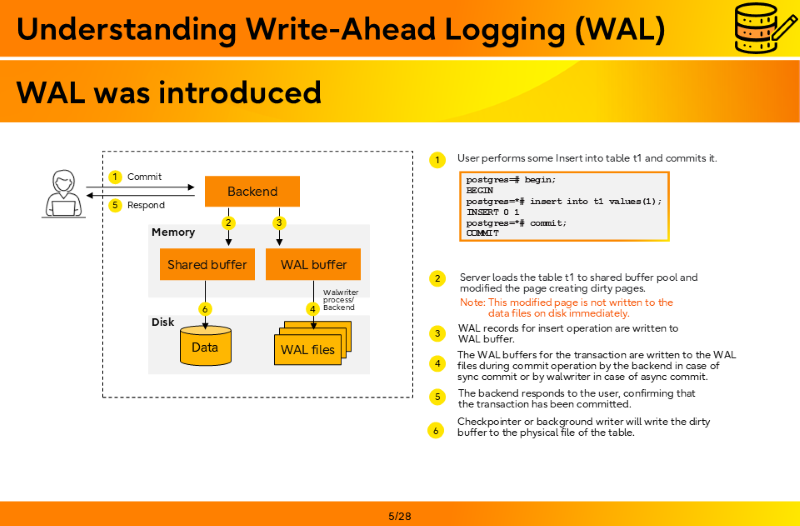
- User performs some Insert into table t1 and commits it.
postgres=# begin; BEGIN postgres=*# INSERT INTO t1 VALUES(1); INSERT 0 1 postgres=*# COMMIT; COMMIT
- Server loads the table t1 to shared buffer pool and modified the page creating dirty pages.
- Write to the disk files. If there are changes in 100 tables, 100 files had to be written.
- The backend responds to the user, confirming that the transaction has been committed.




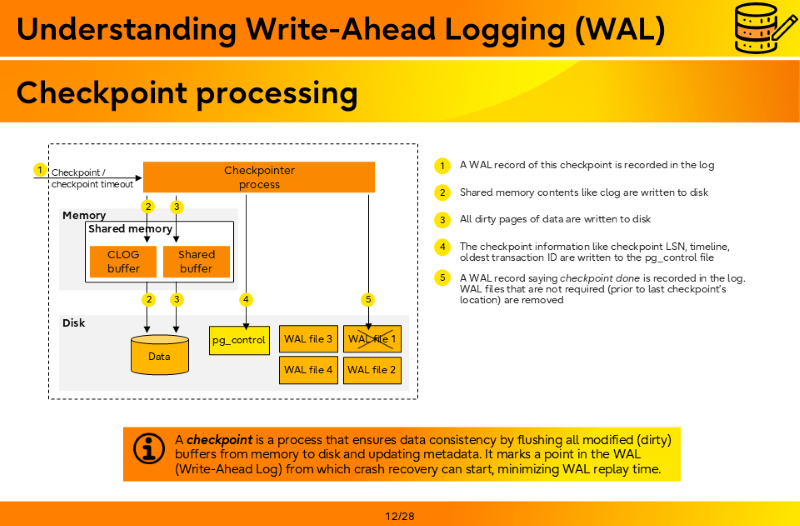
Checkpoint processing
- A WAL record of this checkpoint is recorded in the log
- Shared memory contents like clog are written to disk
- All dirty pages of data are written to disk
- The checkpoint information like checkpoint LSN, timeline, oldest transaction ID are written to the pg_control file
- A WAL record saying checkpoint done is recorded in the log. WAL files that are not required (prior to last checkpoint’s location) are removed




WAL Summarizer process
- The WAL Summarizer process was introduced in PostgreSQL 17. It supports incremental backups, tracks changes to all database blocks (including relations and visibility maps) and writes these modifications to WAL summary files located in the pg_wal/summaries directory
- The WAL Summarizer process operates as follows:
- During each checkpoint, it reads WAL segment files from the previous REDO point to the current REDO point
- It tracks changes to all blocks of all relations (inc. visibility maps) using the WAL segment files
- It writes the summary to WAL summary files located in the pg_wal/summaries/ directory
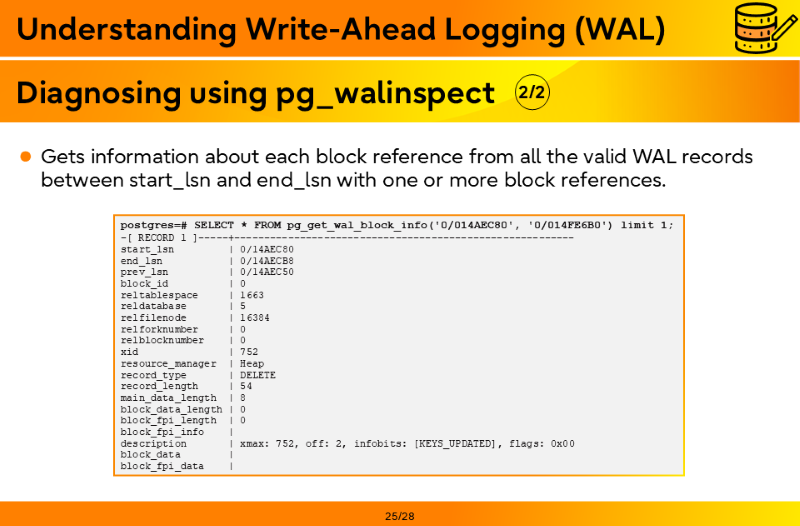
- In the context of the WAL Summarizer process, previous REDO point and current REDO point are referred to as start_lsn and end_lsn, respectively
- Wal summarizer process will be started if summarize_wal guc is set.








Conclusion
 Presenting at PGConf India 2025 was an enriching experience, allowing me to share my insights on WAL with a vibrant community of PostgreSQL enthusiasts. I tried to encapsulate the essence of WAL, from its fundamental concepts to its critical role in ensuring data integrity and performance. By exploring the various components, configurations, and diagnostic tools associated with WAL, I aimed to provide a comprehensive understanding that attendees could apply in their own database environments.
Presenting at PGConf India 2025 was an enriching experience, allowing me to share my insights on WAL with a vibrant community of PostgreSQL enthusiasts. I tried to encapsulate the essence of WAL, from its fundamental concepts to its critical role in ensuring data integrity and performance. By exploring the various components, configurations, and diagnostic tools associated with WAL, I aimed to provide a comprehensive understanding that attendees could apply in their own database environments.
I hope that sharing the slides here serve as a valuable resource for anyone looking to deepen their knowledge of PostgreSQL's WAL mechanism. Thank you for joining me on this journey through the intricacies of WAL!

 PostgreSQL Insider
PostgreSQL Insider 
