

 Fujitsu's global PostgreSQL Development Team are publishing a series of blogs discussing the latest features implemented in the coming versions of PostgreSQL. I am a member of this team dedicated to community activities, and in this blog, I would like to introduce a feature improvement that is to come out in PostgreSQL 14.
Fujitsu's global PostgreSQL Development Team are publishing a series of blogs discussing the latest features implemented in the coming versions of PostgreSQL. I am a member of this team dedicated to community activities, and in this blog, I would like to introduce a feature improvement that is to come out in PostgreSQL 14.
Background - Dropping relation buffers and buffer pool scanning
Systems configured with large values for the shared_buffers setting are becoming more common. When a large value is set for shared_buffers, failover and WAL replay of certain commands that drop relation buffers (such as VACUUM and TRUNCATE) can take a very long time, because the whole buffer pool must be scanned.
The performance issue can be exacerbated especially if there are multiple transactions (e.g., thousands of transactions) of VACUUM/TRUNCATE executed on a primary server, in which case each transaction truncates a table (VACUUM internally starts a new transaction for each table), and the whole buffer pool is scanned per transaction. Using PostgreSQL 13 for the failover test case, it takes dozens of seconds to reflect the changes to the standby server.
A specific test case example is shown at the later section. Although the performance varies per machine specification, the results of investigation showed that the performance regression in PostgreSQL 13 is directly related to the increase of the shared_buffers size and the number of transactions.
I was responsible for providing a solution to this issue in order to meet a customer requirement with FUJITSU Enterprise Postgres. In parallel, I proposed the design to the OSS community, to generate interest in improving the reliability of PostgreSQL (target version: PostgreSQL 14), specifically regarding the performance issues when dropping relation's buffers mentioned above.
Functional overview – Determining the relation size & buffer lookup
In the patches that I developed, the recovery path created when dropping relation buffers is optimized so that when the number of buffers to be dropped in a relation is below the set threshold, scanning of the whole buffer pool can be avoided. This is done by determining the exact size of the relation to ensure that we don't leave any excess other than the relation being dropped. Once we determine that we have a cached relation size, we lookup the buffers to be invalidated in the buffer mapping hash table.
The path for VACUUM and TRUNCATE are different and required slightly different changes. The VACUUM/autovacuum path is optimized in DropRelFileNodeBuffers() for a single relation. The TRUNCATE path is optimized In DropRelFileNodesAllBuffers() where several relations can be dropped. While the goal of improving the performance is the same, the patches had to be separated, thus two patches were committed for this improvement.

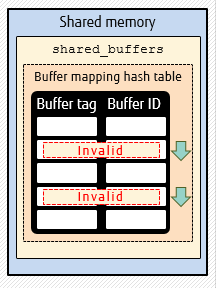
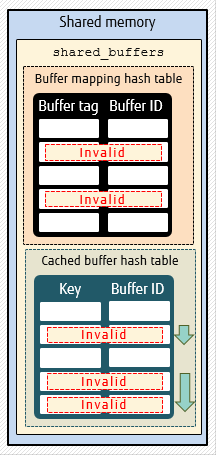
Illustrated above, we have the different behaviors:
- PostgreSQL 13 fully scans the entire shared buffer
- PostgreSQL 14 optimizes only when recovery is involved with VACUUM/TRUNCATE - when the number of buffers to be dropped is below a threshold. Buffer mapping hash table is an existing table in the shared memory
- Starting with FUJITSU Enterprise Postgres 12, both recovery and non-recovery use of VACUUM/TRUNCATE is optimized. Cached buffer hash table is an additional table in the shared memory, and it is scanned once
As mentioned previously, this improvement was originally developed for FUJITSU Enterprise Postgres 12. Note that there are differences in the implementation between this and the patches committed to Postgres core. The feature in FUJITSU Enterprise Postgres 12 covers both the recovery and non-recovery paths of VACUUM and TRUNCATE, using a duplicate buffer hash table, and maintaining a doubly linked list of to-be-invalidated buffers in the shared memory.
However, when I discussed this design with the community, we found out that there is an additional overhead (cost) in buffer allocation, which could compromise general workloads. Hence, I had to follow another approach using the proposed idea of committers in the community (Andres Freund and Amit Kapila) to optimize only the recovery path without the overhead in buffer allocation, by caching the latest known relation size and doing hash table lookups of buffers to be invalidated.
User benefits
The committed feature can be beneficial for huge server systems that use large buffer pools. Among other use cases, the recovery optimization is most helpful when:
- VACUUM command or autovacuum truncated off any of the empty pages at the end of a relation.
- The relation is truncated in the same transaction in which it was created.
- Executing operations where relation files need to be removed, such as TRUNCATE, DROP TABLE, ABORT, CREATE TABLE, etc.
Illustrated in the diagram we have:
- Client executes VACUUM or TRUNCATE on primary.
- The Server process is generated.
- Changes are applied to on shared_buffers by worker processes.
- Changes on shared_buffers are flushed to primary disk by checkpointer or background writer.
- Invalid shared_buffers are deleted (accelerated).
- Changes to primary disk are reflected (replicated) on the secondary disk (accelerated) with WAL shipping.
This improves the recovery performance by more than 100 times in many cases, for example when several small tables are truncated (this was tested with 1000 relations) and the server is configured with a large value for shared_buffers.
The main appeal is that the scanning of the entire buffer pool can be skipped during recovery when there is a cached size of the truncated relation. This reduces the WAL application time during recovery for the use cases mentioned above, regardless of the size of shared_buffers (tested from 128 MB up to 100 GB).
Results for VACUUM failover/recovery performance for 1000 relations
The table below shows the average execution times of VACUUM failover/recovery in PostgreSQL 13 and PostgreSQL 14, and the resulting improvements (all execution times in seconds, aggregating 5 runs).
| shared_buffers | PostgreSQL 13 | PostgreSQL 14 | % improvement |
| 128 MB | 0.306 s | 0.306 s | 0.0% |
| 1 GB | 0.506 s | 0.306 s | 39.5% |
| 20GB | 14.522 s | 0.306 s | 97.9% |
| 100 GB | 66.564 s | 0.306 s | 99.5% |
Results for TRUNCATE failover/recovery performance for 1000 relations
The table below shows the average execution times of TRUNCATE failover/recovery in PostgreSQL 13 and PostgreSQL 14, and the resulting improvements (all execution times in seconds, aggregating 5 runs).
| shared_buffers | PostgreSQL 13 | PostgreSQL 14 | % improvement |
| 128 MB | 0.206 s | 0.206 s | 0.0% |
| 1 GB | 0.506 s | 0.206 s | 59.3% |
| 20GB | 16.476 s | 0.206 s | 98.7% |
| 100 GB | 88.261 s | 0.206 s | 99.8% |
We can see from the benchmarks above that the results for the PostgreSQL 14 were constant for all shared_buffers settings for both VACUUM and TRUNCATE. Scanning and invalidating buffers is no longer dependent on the size of the shared buffer. For further details about this test case and specifications, refer to the community thread here.
Behind the scenes - Working with community members
In the OSS community, committers like Tom Lane, Robert Haas, Andres Freund, Thomas Munro, and Amit Kapila![]() contributed major points for discussion on this solution. Reviewers like Kyotaro Horiguchi and Takayuki Tsunakawa helped me finalize the patches for them to make it simpler, high-quality code.
contributed major points for discussion on this solution. Reviewers like Kyotaro Horiguchi and Takayuki Tsunakawa helped me finalize the patches for them to make it simpler, high-quality code.
I also dedicated a lot of time to respond to reviewers' comments and to post evidence of performance improvements using my test cases and test results. It took almost a year to have the feature committed because it underwent major changes, and I had to convince the community using the tests to prove that the patches I submitted were of high quality.
This experience was both challenging and fulfilling, since some of the feedbacks resulted in major changes to my initial code. The thrill of community work is that there are often conflicting ideas and reviews at the start, but eventually we arrive at a consensus. I would have not been able to successfully close my project without the critical feedback and continued support of reviewers and committers.
As part of the roadmap in Fujitsu's global PostgreSQL Development Team, we target to improve the reliability of PostgreSQL, especially against outages and occurrence of failovers. In this project, I was able to successfully commit the patches under the mentorship of Amit Kapila and Takayuki Tsunakawa. To confirm that my tests were valid, other members from my team also re-executed them and posted the results to the community mailing list thread. The committed patches were my second and third major features to be committed. It feels very fulfilling to see my code reflected in the PostgreSQL core code. It definitely boosted my confidence to continue to contribute to this community.
Looking into the future – Further improvement on caching relation sizes
There is an ongoing discussion and development by a committer, Thomas Munro, about providing a shared cache for relation sizes. If the development goes well, this will pave the way to possibly extending my features to cover the non-recovery paths or normal operations of VACUUM and TRUNCATE.
Fujitsu's global PostgreSQL Development Team has a list of development items in the roadmap that are aimed to be integrated to PostgreSQL core. These items accommodate Fujitsu's customer needs as well as contribute to the PostgreSQL community. We look forward to sharing more about our development work in the near future.

