

 A fundamental part of the Logical Replication PUBLISHER/ SUBSCRIBER model design is how background worker processes are used to implement a subscription. This blog gives some background about the subscription worker processes and summarises some of the enhancements that we have made to the Tablesync Worker.
A fundamental part of the Logical Replication PUBLISHER/ SUBSCRIBER model design is how background worker processes are used to implement a subscription. This blog gives some background about the subscription worker processes and summarises some of the enhancements that we have made to the Tablesync Worker.
Much of what we have been doing in this area is not user-facing; it is necessary to give some background information so that our changes can be described in context.
Workers
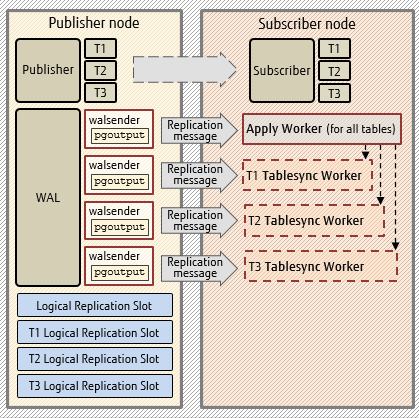
SUBSCRIPTION replication is performed by two kinds of background workers:
- An Apply Worker
- One or more Tablesync Workers.
The CREATE SUBSCRIPTION command launches a single Apply Worker. This Apply Worker then launches N x Tablesync Workers (one for each table that the SUBSCRIPTION subscribes to).
The Apply Worker process is long-lived - it exists (in the absence of errors) until the SUBSCRIPTION is dropped. The Tablesync Worker processes are transient - each Tablesync Worker only exists for the synchronization phase of the associated table.
The primary purpose of the Tablesync Worker is to initialize the replicated table by doing a COPY of all rows of the published table (at the time of the CREATE SUBSCRIPTION).
The Tablesync Workers and Apply Worker are each capable of receiving and handling pending replication protocol messages – e.g., messages for replicating the CRUD (Create, Read, Update, Delete) operations at the subscriber side.
Example
Usually, you won’t be quick enough to observe the Tablesync Worker processes before they have already completed, but in case you do, here is what the processes might look like for a subscription with multiple tables. (The walsenders are on the publisher node; the replication workers are on the subscriber node).
postgres: walsender postgres ::1(40932) START_REPLICATION
postgres: logical replication worker for subscription 16571 sync 16403 B
postgres: walsender postgres ::1(40934) COPY
postgres: logical replication worker for subscription 16571 sync 16385 B
postgres: walsender postgres ::1(40936) COPY
A The Apply Worker and its walsender
B 2 x Tablesync Workers and their walsenders
Tablesync states
Replication messages may be arriving continuously, even at the same time as the Tablesync Workers are launching and copying. All the workers are feeding off different streams containing the same replication messages, so depending on the timings, it can happen that the Tablesync Worker is either behind or ahead of the Apply Worker for processing the same messages.
To avoid stepping on each other’s toes (double handling of the same message) the Apply Worker and Tablesync Worker negotiate with each other via states to synchronize themselves.
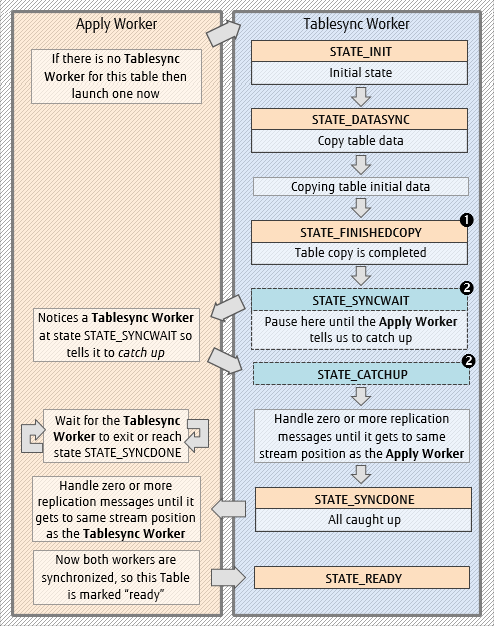
Notes for the diagram:
- STATE_FINISHEDCOPY is a new state introduced for PostgreSQL 14.
- Some of these Tablesync States are in shared memory (SYNCWAIT, CATCHUP), and others are in a system catalog.
You can interrogate the pg_subscription_rel system catalog to see the Tablesync State (srsubstate) of each subscribed table.
Example
Here is a subscription with 5 tables. The states were captured at a point when 2 of the Tablesync Workers were still copying data.
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+------------
16571 | 16385 | d |
16571 | 16403 | d |
16571 | 16412 | r | 0/11A31128
16571 | 16421 | r | 0/11A2F350
16571 | 16394 | r | 0/11A2F510
(5 rows)
The output above shows the top 2 Tablesync Workers are still copying data, and 3 Tablesync Workers have completed
The state codes are as follows:
| Code | State |
| i | STATE_INIT |
| d | STATE_DATASYNC |
| f | STATE_FINISHEDCOPY (see note 1 above) |
| w | STATE_SYNCWAIT |
| c | STATE_CATCHUP |
| s | STATE_SYNCDONE |
| r | STATE_READY |
The copy_data = false option
As described, the main purpose of the Tablesync Worker is for the initial table data COPY and synchronization. But this is optional - if the SUBSCRIPTION is created with the copy_data = false option, then all the copy processing will be skipped. In this case, the Tablesync Worker is launched with the state already set as STATE_READY – this will cause the Tablesync Worker to exit immediately.
Tablesync errors
If an error occurs during the Tablesync Worker processing (e.g., there could be a Primary Key violation of data during the DATASYNC phase), then the Tablesync Worker will log the error and exit.  The Apply Worker is aware of all the subscribed tables which have not yet attained the STATE_READY, so after a moment the missing Tablesync Worker will be detected, and another one will be (optimistically) re-launched to replace it.
The Apply Worker is aware of all the subscribed tables which have not yet attained the STATE_READY, so after a moment the missing Tablesync Worker will be detected, and another one will be (optimistically) re-launched to replace it.
If the same (or any) error happens again, then this replacement Tablesync Worker will also fail and another re-launched Tablesync Worker will take its place!
This error-launch-error-launch loop will keep happening until either:
- The cause of the problem (e.g., PK violation) is resolved so that the Tablesync Worker can complete without error, or
- The problem table is removed from the SUBSCRIPTION
Tablesync Enhancements
The Fujitsu OSS team is working with the open-source community to enhance the Logical Replication for PostgreSQL. Some of the improvements we have contributed for the Tablesync Worker include the following:
Permanent slots and origin tracking
Logical Replication Slots are the mechanism used by Postgres for keeping track of what master WAL files need to be retained for the SUBSCRIPTION’s WAL Senders. Each slot represents the stream of changes to be replayed in the order they were made on the origin server. Slots also hold information about the current position within that stream.
 Each Tablesync Worker has an associated Replication Slot. These were previously temporary slots, in memory only for the life of each Tablesync Worker. If the Tablesync Worker unexpectedly crashed, then the slot was lost, and when the replacement Tablesync Worker launched it would start with a newly created temporary slot and then repeat everything again as if seen for the first time.
Each Tablesync Worker has an associated Replication Slot. These were previously temporary slots, in memory only for the life of each Tablesync Worker. If the Tablesync Worker unexpectedly crashed, then the slot was lost, and when the replacement Tablesync Worker launched it would start with a newly created temporary slot and then repeat everything again as if seen for the first time.
The Tablesync Worker has been modified to now use permanent slots instead of temporary slots. Replication origin information is persisted in the slots for keeping track of what data has already been replicated, so by using the permanent slots, it means that after a crash/restart it is now possible to pick up replication again from the most recently recorded checkpoint.
These slots have generated names: pg_<subscription OID>_sync_<table relid>_<system id>
Example: pg_16571_sync_16403_6992073143355919431
The following other enhancements are also possible now only because the Tablesync Worker is using permanent slots.
A new state - STATE_FINISHEDCOPY
The initial data copy phase can be very expensive. For the default case (copy_data = true) the Tablesync Worker does COPY of all table data. This could be GB of data and may take a long time to complete.
 As described above, if any error occurs within the Tablesync Worker then a new Tablesync Worker gets re-launched to replace it. Previously, this meant that the restarted Tablesync Worker would start again from the DATASYNC state and so COPY would occur all over again.
As described above, if any error occurs within the Tablesync Worker then a new Tablesync Worker gets re-launched to replace it. Previously, this meant that the restarted Tablesync Worker would start again from the DATASYNC state and so COPY would occur all over again.
A new Tablesync state STATE_FINISHEDCOPY has been introduced.
This state is assigned when the copy phase has completed, and the table data is committed. Because the Tablesync’s Slot is now permanent, the origin information is also updated at this commit checkpoint.
Now, after this FINISHEDCOPY state is set, if any subsequent error happens causing the Tablesync Worker to be re-launched, the code logic knows that the (expensive) copy step has already completed – it does not repeat it because the replication re-starts from the last known origin.
Multi-transaction support
Previously, Tablesync Workers ran entirely in a single transaction which either was committed or not depending if any error occurred.
The Tablesync Worker has been enhanced to support multiple transactions:
- Now the initial copy part (DATASYNC-FINISHEDCOPY) runs in one transaction.
- Now the replication message-handling parts run in their own transactions (this makes Tablesync Worker processing of replication messages the same as for the Apply Worker)
Combined with the new FINISHEDCOPY state this means the copy part can be independently committed. Also, because the replication origin tracking is recorded in the permanent slot, it means any already-committed data can be skipped.
Miscellaneous contributions
Fujitsu has also contributed numerous other bugfixes and small improvements in the PostgreSQL Logical Replication area, and we regularly participate in reviews of other contributed patches.
Here are some more PostgreSQL 14 changes we have authored, with the help of others:
- Rename the logical replication global "wrconn"

- Improve style of some replication-related error messages
- Fix dangling pointer reference in stream_cleanup_files
- Clarify comment in tablesync.c
- Fix deadlock for multiple replicating truncates of the same table
- Use Enums for logical replication message types at more places
Benefits
The improvements made to the Tablesync Worker help to make Logical Replication:
- More robust in case of failure
- More efficient (for scenarios able to avoid expensive table re-COPY if already committed)
- More consistent (with multi-transaction logic same as that of the Apply Worker)
- More stable (through bug fixes)
For the Future
The Fujitsu OSS team is continuing to help make Logical Replication improvements, and we already have several enhancements in the pipeline which we hope to get committed in PostgreSQL 15.
Stay tuned for more blogs on this topic.

