

This often includes noticeable questions such as where does such and such memory component exist, is a particular memory allocated from shared memory (accessible across all PostgreSQL processes) or individual process memory, and many more.
In this post, I have consolidated information from different parts of the documentation to produce a simplified explanation of what are some of the significant memory areas of a PostgreSQL instance and how are they allocated.
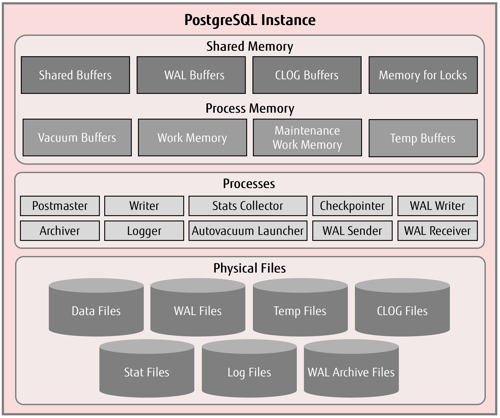
Here is a pictorial view of a PostgreSQL instance depicting the memory areas, server background processes and the underlying database files.
The interesting point to note is all the memory components which are listed below are allocated in the RAM.
Shared Buffers
It is always faster to read or write data in memory than on any other media. A database server also needs memory for quick access to data, whether it is READ or WRITE access. In PostgreSQL, this is referred to as "shared buffers" and is controlled by the parameter shared_buffers. The amount of RAM required by shared buffers is always locked for the PostgreSQL instance during its lifetime. The shared buffers are accessed by all the background server and user processes connecting to the database.
The data that is written or modified in this location is called "dirty data" and the unit of operation being database blocks (or pages), the modified blocks are also called "dirty blocks" or "dirty pages". Subsequently, the dirty data is written to disk containing physical files to record the data in persistent location and these files are called "data files".
WAL Buffers
The write ahead log (WAL) buffers are also called "transaction log buffers", which is an amount of memory allocation for storing WAL data. This WAL data is the metadata information about changes to the actual data, and is sufficient to reconstruct actual data during database recovery operations. The WAL data is written to a set of physical files in persistent location called "WAL segments" or "checkpoint segments".
The WAL buffers memory allocation is controlled by the wal_buffers parameter, and it is allocated from the operating system RAM. Although this memory area is also accessible by all the background server and user processes, it is not part of the shared buffers. The WAL buffers are external to the shared buffers and are very small when compared to shared buffers. The WAL data is first modified (dirtied) in WAL buffers before it is written to WAL segments on disk. If it is left to default settings, then it is allocated with a size of 1/16th of the shared buffers.
CLOG Buffers
CLOG stands for "commit log", and the CLOG buffers is an area in operating system RAM dedicated to hold commit log pages. The commit log pages contain log of transaction metadata and differ from the WAL data. The commit logs have commit status of all transactions and indicate whether or not a transaction has been completed (committed).
There is no specific parameter to control this area of memory. This is automatically managed by the database engine in tiny amounts. This is a shared memory component, which is accessible to all the background server and user processes of a PostgreSQL database.
Memory for Locks / Lock Space
This memory component is to store all heavyweight locks used by the PostgreSQL instance. These locks are shared across all the background server and user processes connecting to the database. A non-default larger setting of two database parameters namely max_locks_per_transaction and max_pred_locks_per_transaction in a way influences the size of this memory component.
Vacuum Buffers
This is the maximum amount of memory used by each of the autovacuum worker processes, and it is controlled by the autovacuum_work_mem database parameter. The memory is allocated from the operating system RAM and is also influenced by the autovacuum_max_workers database parameter. The setting of autovacuum_work_mem should be configured carefully as autovacuum_max_workers times this memory will be allocated from the RAM. All these parameter settings only come into play when the auto vacuum daemon is enabled, otherwise, these settings have no effect on the behavior of VACUUM when run in other contexts. This memory component is not shared by any other background server or user process.
Work Memory
This is the amount of memory reserved for either a single sort or hash table operation in a query and it is controlled by work_mem database parameter. A sort operation could be one of an ORDER BY, DISTINCT or Merge join and a hash table operation could be due to a hash-join, hash based aggregation or an IN subquery.
A single complex query may have many number of such sort or hash table operations, and as many chunks of memory allocations defined by the work_mem parameter will be created for each of those operations in a user connection. It is for this reason, that work_mem should not be declared to a very big value as it might lead to aggressively utilizing all the available memory from operating system for a considerably huge query, thereby starving the operating system of RAM which might be needed for other processes.
Maintenance Work Memory
This is the maximum amount of memory allocation of RAM consumed for maintenance operations. A maintenance operation could be one of the VACUUM, CREATE INDEX or adding a FOREIGN KEY to a table. The setting is controlled by the maintenance_work_mem database parameter.
A database session could only execute any of the abovementioned maintenance operations at a time and a PostgreSQL instance does not normally execute many such maintenance operations concurrently. Hence, this parameter can be set significantly larger than work_mem parameter. A point of caution is to not set this memory to a very high value, which will allocate as many portions of memory allocations as defined by the autovacuum_max_workers parameter in the event of not configuring the autovacuum_work_mem parameter.
Temp Buffers
A database may have one or more temporary tables, and the data blocks (pages) of such temporary tables need a separate allocation of memory to be processed in. The temp buffers serve this purpose by utilizing a portion of RAM, defined by the temp_buffers parameter. The temp buffers are only used for access to temporary tables in a user session. There is no relation between temp buffers in memory and the temporary files that are created under the pgsql_tmp directory during large sort and hash table operations.
I believe that the explanation of each of the memory components of a PostgreSQL instance has offered sufficient insight into where and how each of the memory areas are allocated and utilized.
Our database experts are on hand to answer your questions and ensure peace of mind with your PostgreSQL-based database. Call us on +612 9452 9191 if you would like to discuss how we can help you directly.
