It was an exciting experience to share the stage with my Fujitsu coleague Nishchay Kothari PGConf.dev 2025 to present our session on the topic of Learned Indexes in PostgreSQL. For those that could not attend, we would like to share our presentation.
We discussed the theoretical foundations of learned indexes and the practical challenges involved in integrating them with PostgreSQL’s extensible indexing framework.
We were thrilled to engage the PostgreSQL developer community on a topic that is rapidly gaining traction in modern database research. Learned indexes are a novel class of indexing techniques that leverage machine learning models—often lightweight regression trees or neural networks—to predict the position of a data item, rather than relying solely on traditional data structures like B-trees or hash indexes.
This cutting-edge approach leverages machine learning models to optimize database indexing, which can lead to potential performance and storage gains under certain workloads.
What we talked about
Our talk delved into both the theoretical foundations of learned indexes and the practical challenges and considerations involved in integrating them with PostgreSQL’s extensible indexing framework.
We explored the integration of learned indexes into PostgreSQL, delving into the motivation behind exploring alternatives to traditional indexing methods like B-Trees, outlining the theoretical foundations of learned indexes, and examining real-world research and implementations such as ALEX and CARMI.
But we also highlighted the architectural challenges of integrating these models into PostgreSQL when it comes to the issues of increasing data complexity and performance demands. All in all, we offered a candid assessment of the current feasibility and future potential of learned indexes in PostgreSQL environments.
Below, you'll find the slides from our presentation at PGConf.dev 2025 in Montreal.
Side by sideClick to view the slides side by side
Top to bottomClick to view the slides in vertical orientation
How to upgrade replication clusters without downtime
Gary Evans and Nischay Kothari
Agenda
Motivation for exploring alternative indexing approaches
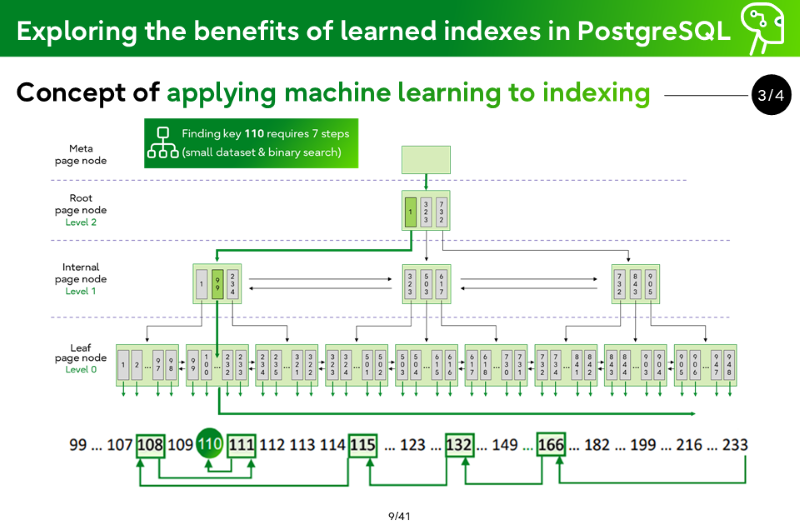
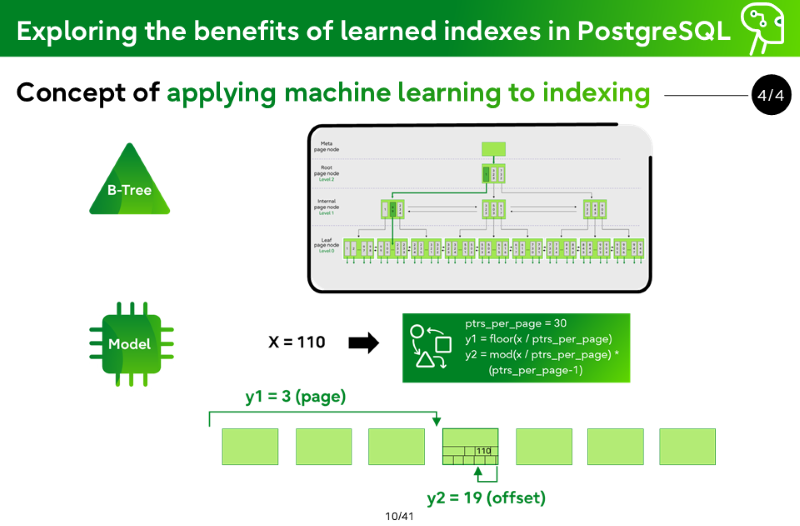
Concept of Learned Indexes
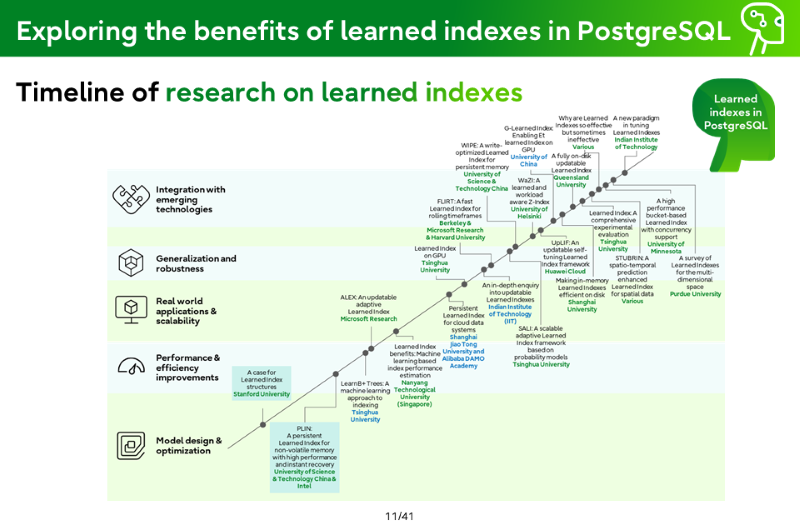
Studies that have brought a focus to Learned Indexes
Integrating Learned Indexes into PostgreSQL and its Challenges
Q&A
Motivation for exploring alternative indexing approaches
Index Access Method API
B-Tree
BRIN
GIN
GiST
SP-Gist
Learned Index
Ever-changing challenges
Data growth & complexity
Databases are handling increasingly complex datasets and workloads (e.g., big data, real-time analytics, cloud environments)
Traditional indexing methods often struggle to scale with these demands
Performance demands
The need for faster query response times and optimized storage is more critical than ever in the competitive database landscape
Learned indexes can be the next frontier for performance enhancement
Shift toward data-driven optimization
Machine learning is being adopted across various layers of database management systems (e.g., query optimization, storage management)
Machine learning advancements
Deep learning and regression models have matured, making them more viable for production environments
Machine learning tools are more accessible and scalable with modern infrastructure
Some of the comments (from Twitter https://twitter.com/schrockn/status/940037656494317568): "Jeff Dean and co at GOOG just released a paper showing how machine-learned indexes can replace B-Trees, Hash Indexes, and Bloom Filters. Execute 3x faster than B-Trees, 10-100x less space. Executes on GPU, which are getting faster unlike CPU. Amazing."
Can those ideas be applied to Postgres in its current state? Or it's not really down-to-earth?
A big problem when critically evaluating any complicated top-down model in the abstract is that it's too easy for the designer to hide *risk* (perhaps inadvertently). If you are allowed to make what amounts to an assumption that you have perfect foreknowledge of the dataset, then sure, you can do a lot with that certainty. You can easily find a way to make things faster or more space efficient by some ridiculous multiple that way (like 10x, 100x, whatever).
None of these papers ever get around to explaining why what they've come up with is not simply fool's gold. The assumption that you can have robust foreknowledge of the dataset seems incredibly fragile, even if your model is *almost* miraculously good. I have no idea how fair that is. But my job is to make Postgres better, not to judge papers. My mindset is very matter of fact and practical.
--
Peter Geoghegan
Tipping point scenarios
Model robustness improves
ALEX and similar approaches adapt online to distribution shifts.
Fallbacks (e.g., B-Tree segments where prediction fails) minimize fragility.
If you can safely assume bounded error, the risk Peter talks about diminishes.
Hardware makes B-Trees less dominant
B-Trees are optimised for cache line access patterns.
With new memory tech (e.g., HBM, CXL), prediction-based access may outperform pointer chasing.
Predictive indexes get embedded in real systems
PostgreSQL extensions like PGM Index or even future learned AMs (access methods) could provide hybrid strategies.
You could apply learned models only for hot paths or static segments, leaving the rest to traditional methods — reducing the fool’s gold risk.
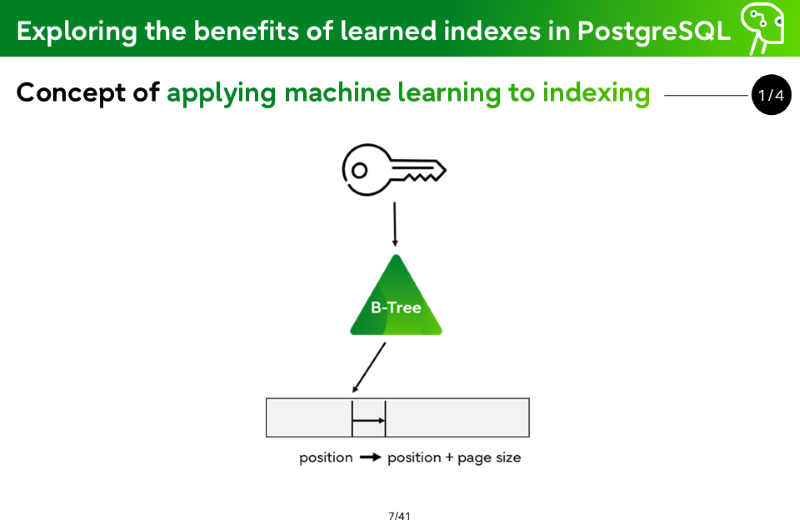
Concept of applying machine learning to indexing
B-Tree: position → position + page size
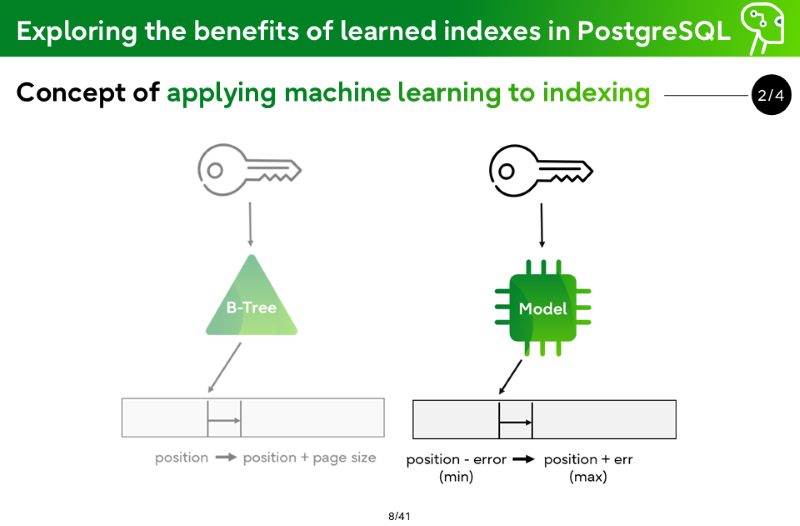
Concept of applying machine learning to indexing
B-Tree: position → position + page size
Model: position - error (min) → position + err (max)
LIDER: An Efficient High-dimensional Learned Index for Large-scale Dense Passage Retrieval; Research; Yifan Wang20; Haodi Ma20; Daisy Zhe Wang20
Learned Index Benefits: Machine Learning Based Index Performance Estimation; Research; Jiachen Shi13; Gao Cong13; Xiaoli Li10
PLIN: A Persistent Learned Index for Non-Volatile Memory with High Performance and Instant Recovery; Research; Zhou Zhang24; Zhaole Chu23; Peiquan Jin23; Yongping Luo23; Xike Xie23; Shouhong Wan23; Yun Luo18; Xufei Wu18; Peng Zou18; Chunyang Zheng11; Guoan Wu11; Andy Rudoff11
DILI: A Distribution-Driven Learned Index; Research; Pengfei Li2; Hua Lu17; Rong Zhu2; Bolin Ding3; Long Yang16; Gang Pan25
Adaptive Indexing of Objects with Spatial Extent; Research; Fatemeh Zardbani1; Nikos Mamoulis21; Stratos Idreos4; Panagiotis Karras1
DeepJoin: Joinable Table Discovery with Pre-trained Language Models; Research; Yuyang Dong14; Chuan Xiao15; Takuma Nozawa14; Masafumi Enomoto14; Masafumi Oyamada14
LMSFC: A Novel Multidimensional Index based on Learned Monotonic Space Filling Curves; Research; Jian Gao22; Xin Cao22; Xin Yao7; Gong Zhang8; Wei Wang5
Sieve: A Learned Data-Skipping Index for Data Analytics; Research; Yulai Tong9; Jiazhen Liu9; Hua Wang9; Ke Zhou9; Rongfeng He6; Qin Zhang6; Cheng Wang6
Learned Index Benefits: Machine Learning Based Index Performance Estimation; Research; Jiachen Sh13; Gao Cong13; Xiaoli Li10
1: Aarhus University 2: Alibaba Group 3: Data Analytics and Intelligence Lab, Alibaba Group 4: Harvard 5: Hong Kong University of Science and Technology 6: Huawei Cloud Computing Technologies Co., Ltd 7: Huawei Theory Lab 8: Huawei 9: Huazhong University of Science and Technology 10: Institute for Infocomm Research, A*STAR, Singapore/Nanyang Technological University 11: Intel 12: MIT 13: Nanyang Technological University 14: NEC Corporation 15: Osaka University and Nagoya University 16: Peking University 17: Roskilde University 18: Tencent 19: Tsinghua University 20: University of Florida 21: University of Ioannina 22: University of New South Wales 23: University of Science and Technology of China 24: USTC 25: Zhejiang University
PostgreSQL positioning on learned indexes
PostgreSQL’s extensibility
PostgreSQL’s extensible architecture allows the integration of custom indexes, making it easy to experiment with and incorporate machine learning-based indexes
Growing ecosystem of AI and ML in PostgreSQL
Integration of PostgresML (a PostgreSQL extension for machine learning) and other tools shows PostgreSQL’s readiness for machine learning applications
Declarative Partitioning & BRiN
PostgreSQL already supports partitioning and Block Range Indexing which align well with Learned Index concepts
Concurrency control
PostgreSQL's MVCC system would allow Learned Indexes to remain usable even as data evolves
Rich indexing framework
PostgreSQL already supports a wide range of index types (B-tree, GiST, GIN, BRIN, etc.), providing a flexible foundation for integrating learned models alongside traditional methods
Active research community
The PostgreSQL community has a strong focus on innovation and research in database optimization techniques, which can drive the development of learned indexes
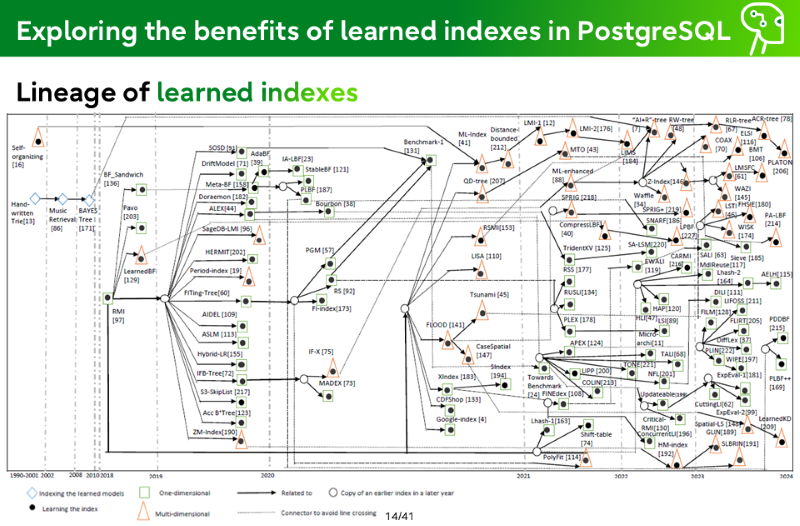
Lineage of learned indexes
Indexing learned models
One-dimensional
→
Related to
Copy of an earlier index in a later year
Learning the index
Multi-dimensional
Connector to avoid line crossing
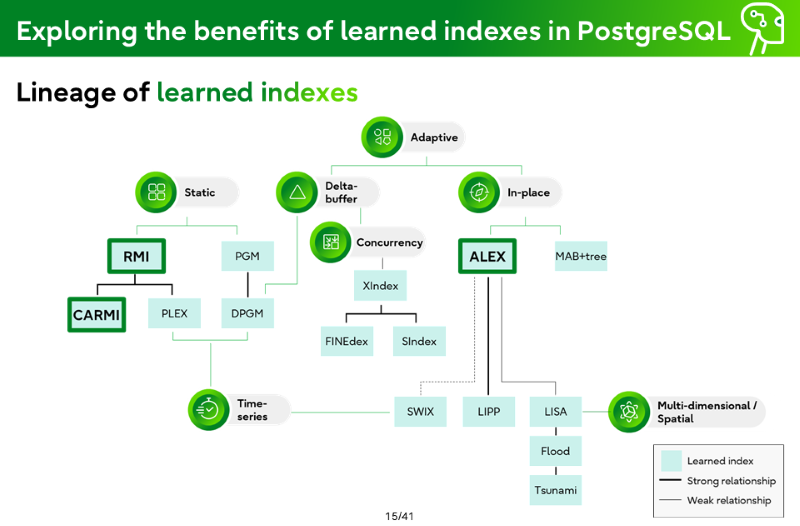
Lineage of learned indexes
Adaptive
Static
Delta-buffer
In-place
Concurrency
Time-series
Multi-dimensional/Spatial
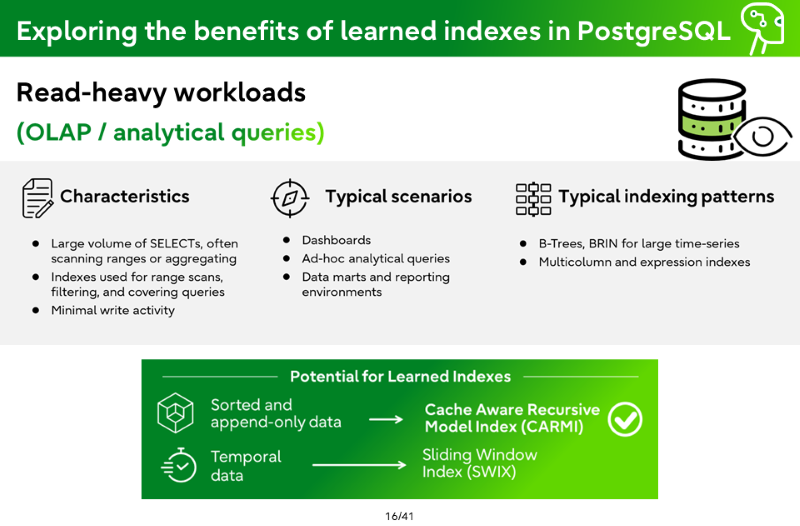
Read-heavy workloads (OLAP / analytical queries)
Characteristics
Large volume of SELECTs, often scanning ranges or aggregating
Indexes used for range scans, filtering, and covering queries
Minimal write activity
Typical scenarios
Dashboards
Ad-hoc analytical queries
Data marts and reporting environments
Typical indexing patterns
B-Trees, BRIN for large time-series
Multicolumn and expression indexes
Potential for Learned Indexes
Sorted and append-only data → Cache Aware Recursive Model Index (CARMI)
Temporal data → Sliding Window Index (SWIX)
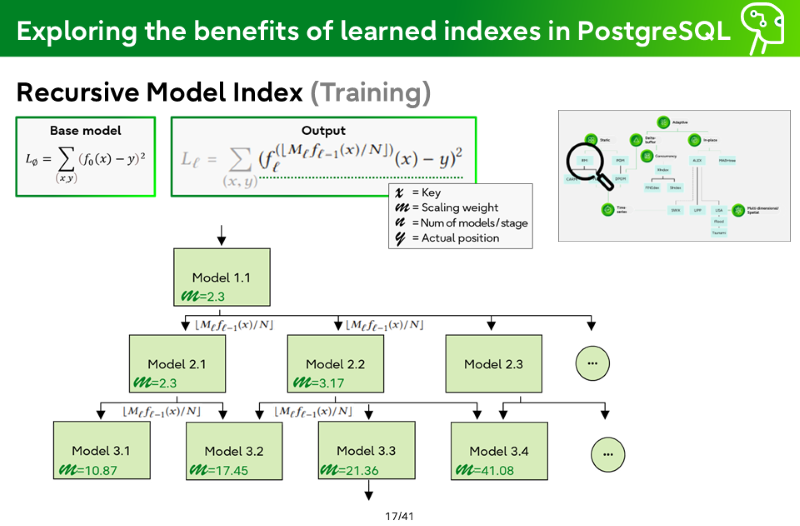
Recursive Model Index (Training)
x = Key
m = Scaling Weight
n = = Num of models / stage
y = = Actual position
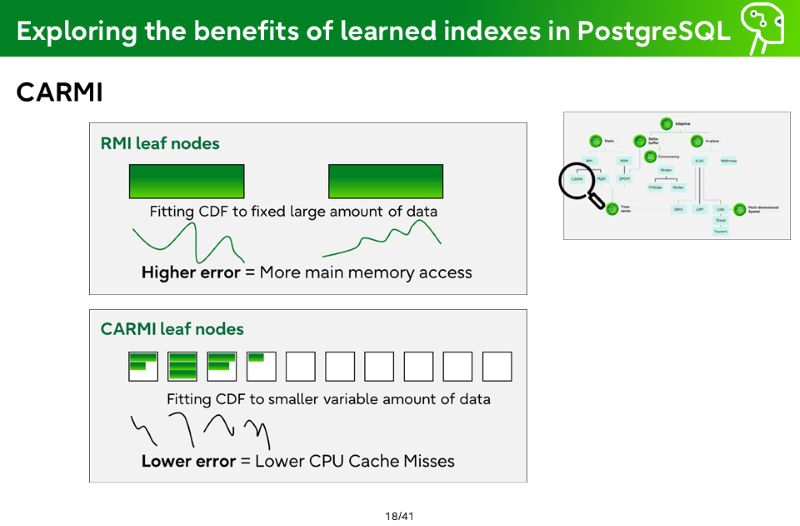
CARMI
RMI leaf nodes
Fitting CDF to fixed large amount of data
Higher error = More main memory access
CARMI leaf nodes
Fitting CDF to smaller variable amount of data
Lower error = Lower CPU Cache Misses
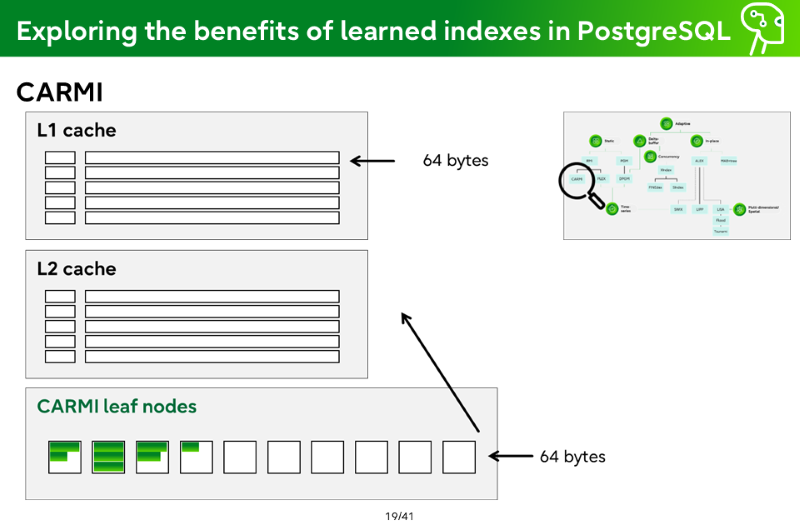
CARMI
L1 cache
L2 cache
CARMI leaf nodes
CPU cache access = 1-10 nano seconds
Main memory = 100-200 nano seconds
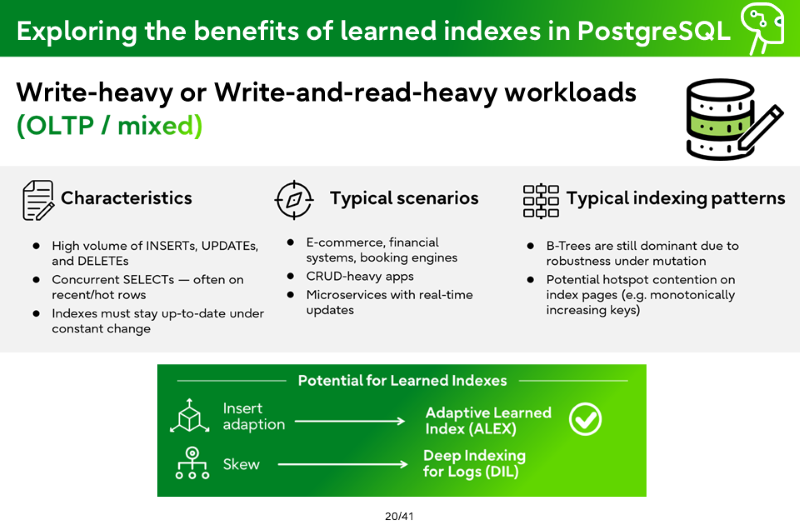
Write-heavy or Write-and-read-heavy workloads (OLTP / mixed)
Characteristics
High volume of INSERTs, UPDATEs, and DELETEs
Concurrent SELECTs — often on recent/hot rows
Indexes must stay up-to-date under constant change
Typical scenarios
E-commerce, financial systems, booking engines
CRUD-heavy apps
Microservices with real-time updates
Typical indexing patterns
B-Trees are still dominant due to robustness under mutation
Potential hotspot contention on index pages (e.g. monotonically increasing keys)
Potential for Learned Indexes
Insert adaption → Adaptive Learned Index (ALEX)
Skew → Deep Indexing for Logs (DIL)
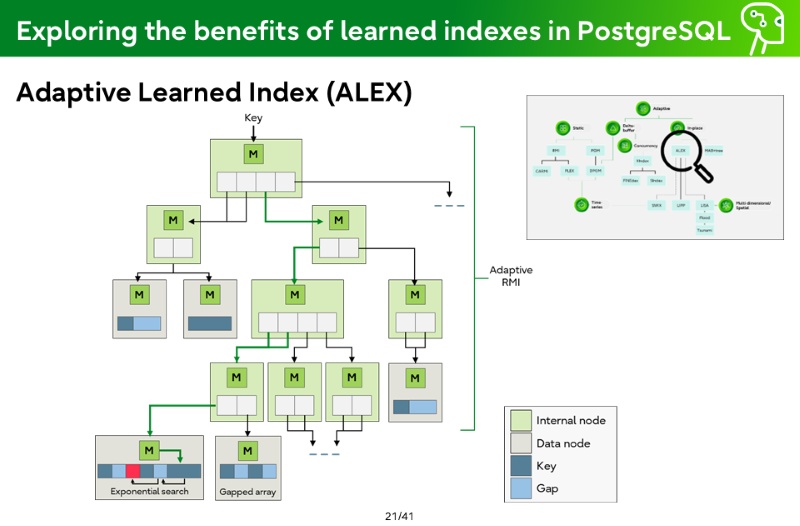
Adaptive Learned Index (ALEX)
Internal node
Data node
Key
Gap
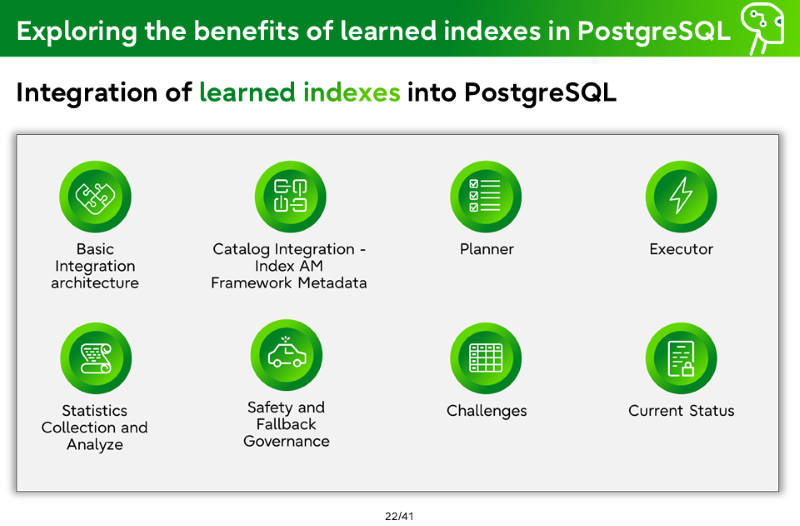
Integration of learned indexes into PostgreSQL
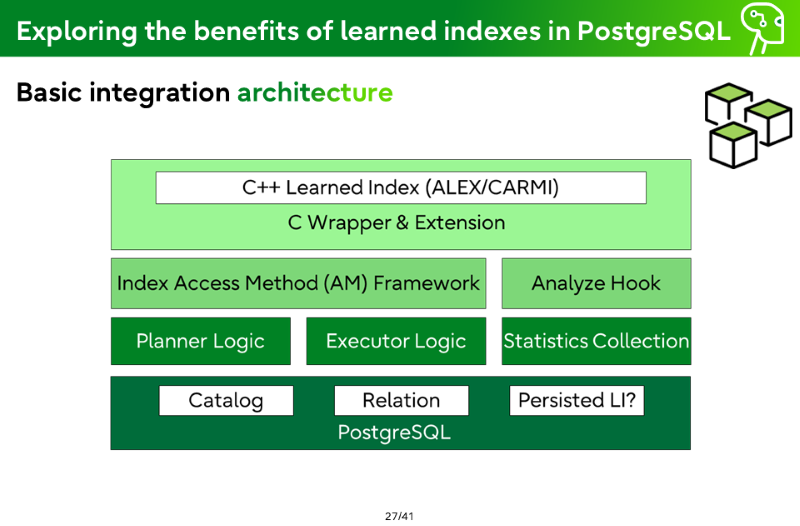
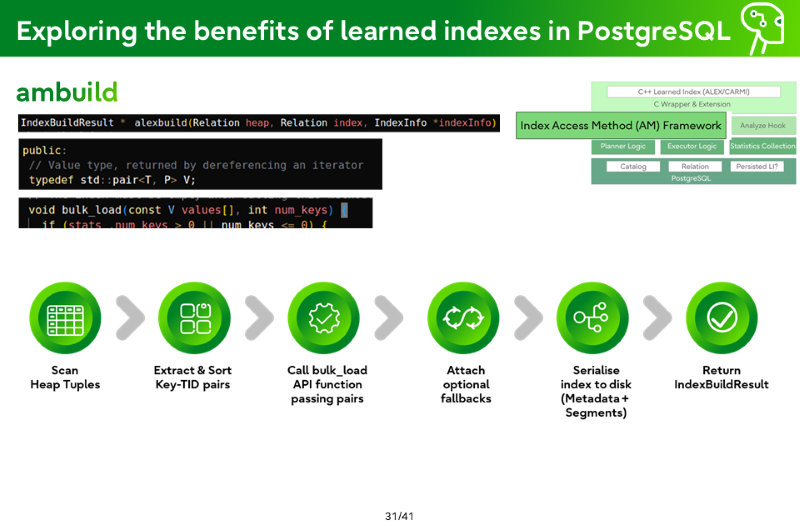
Basic Integration architecture
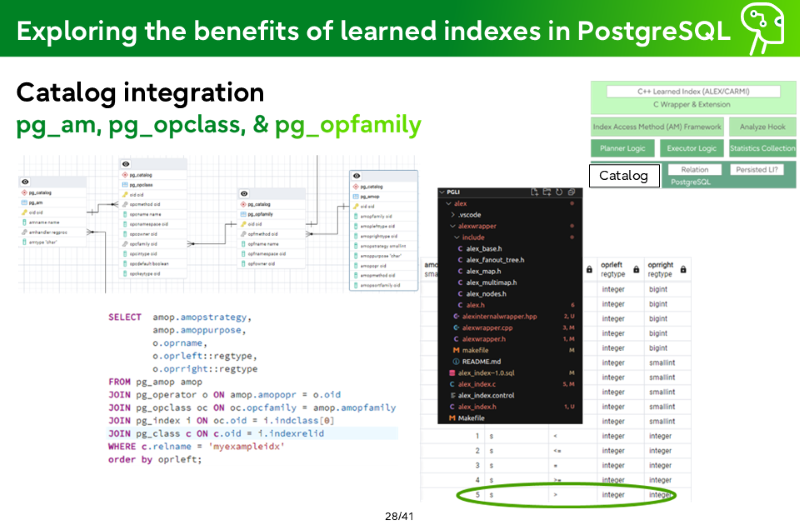
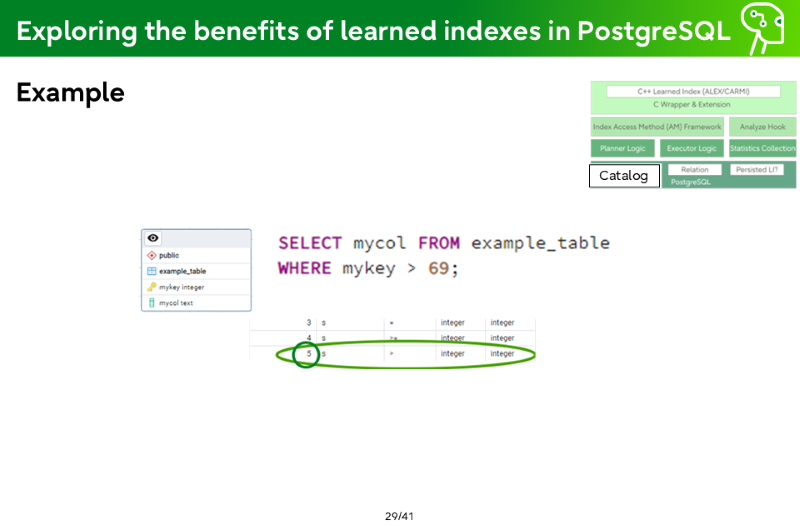
Catalog Integration - Index AM Framework Metadata
Planner
Executor
Statistics Collection and Analyze
Safety and Fallback Governance
Challenges
Current Status
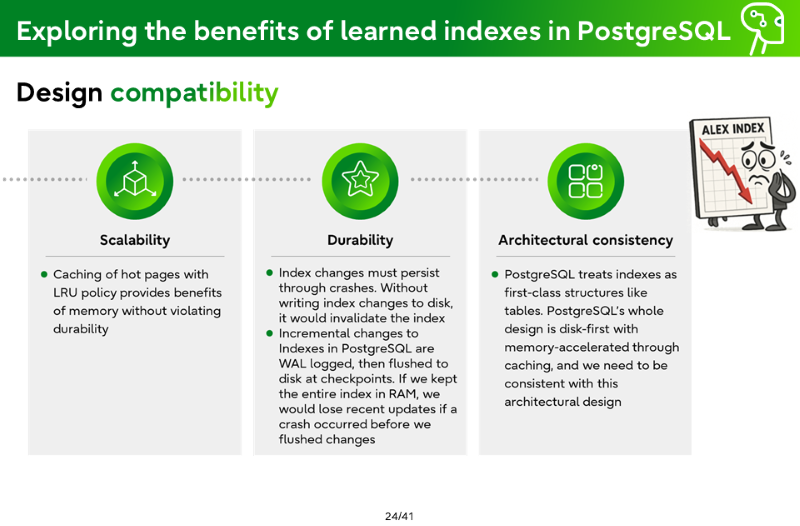
Architectural design compatibility
Problem: Architectural Incompatibility between PostgreSQL & ALEX
ALEX assumes full index (models + payloads) reside in memory for optimal performance
PostgreSQL enforces a disk-first architecture, relying on shared buffers and OS caching for performance
Index persistence is mandatory in PostgreSQL for crash recovery, MVCC visibility, and WAL integration
ALEX lacks native support for PostgreSQL’s page/block storage model, making it incompatible with its buffer manager and write-ahead logging (WAL)
Bridging the gap would require rearchitecting ALEX to support disk paging and metadata versioning
Design compatibility
Scalability
Caching of hot pages with LRU policy provides benefits of memory without violating durability
Durability
Index changes must persist through crashes. Without writing index changes to disk, it would invalidate the index
Incremental changes to Indexes in PostgreSQL are WAL logged, then flushed to disk at checkpoints. If we kept the entire index in RAM, we would lose recent updates if a crash occurred before we flushed changes
Architectural consistency
PostgreSQL treats indexes as first-class structures like tables. PostgreSQL’s whole design is disk-first with memory-accelerated through caching, and we need to be consistent with this architectural design
Possible In-memory ALEX extension use cases
Accelerating queries on Parquet files via pg_parquet
Build in-memory ALEX indexes on key columns (e.g., user_id, event_time)
Speeds up filters and joins that aren’t pushed down
Temporary indexing for intermediate results
Fast lookup or range scan on CTEs or temp tables in analytical workflows
Append-heavy workloads on mostly sorted data
Ideal for logs, time-series, or streaming inserts into memory
Join acceleration on foreign tables (FDW scans)
Indexes remote scan buffers on-demand to optimise joins
Query acceleration in ML feature stores
High-throughput lookups on in-memory feature sets for training/inference
Vector search pre-filtering
Filters metadata before applying expensive similarity operations
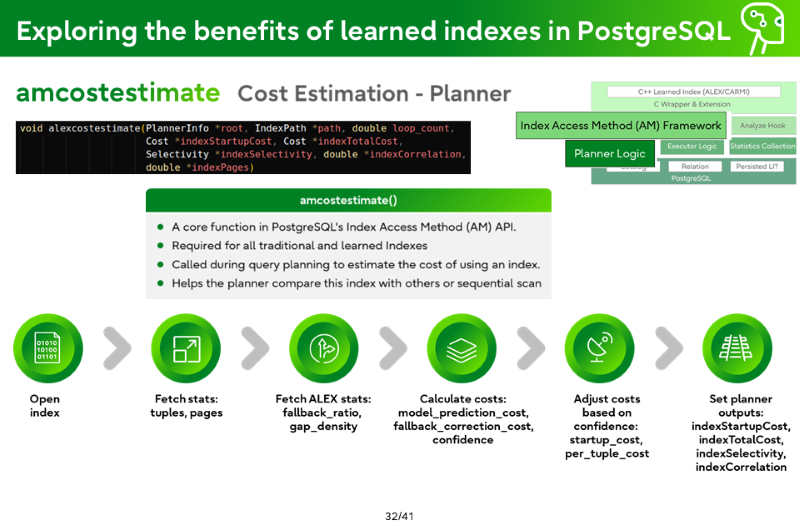
Adjust costs based on confidence: startup_cost, per_tuple_cost
Set planner outputs: indexStartupCost, indexTotalCost, indexSelectivity, indexCorrelation
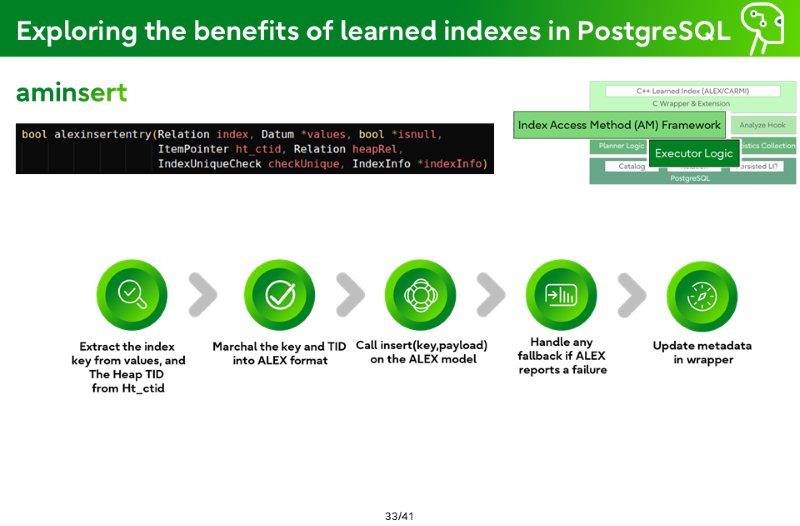
aminsert
Extract the index key from values, and the Heap TID from Ht_ctid
Marshal the key and TID into ALEX format
Call insert(key,payload) on the ALEX model
Handle any fallback if ALEX reports a failure
Update metadata in wrapper
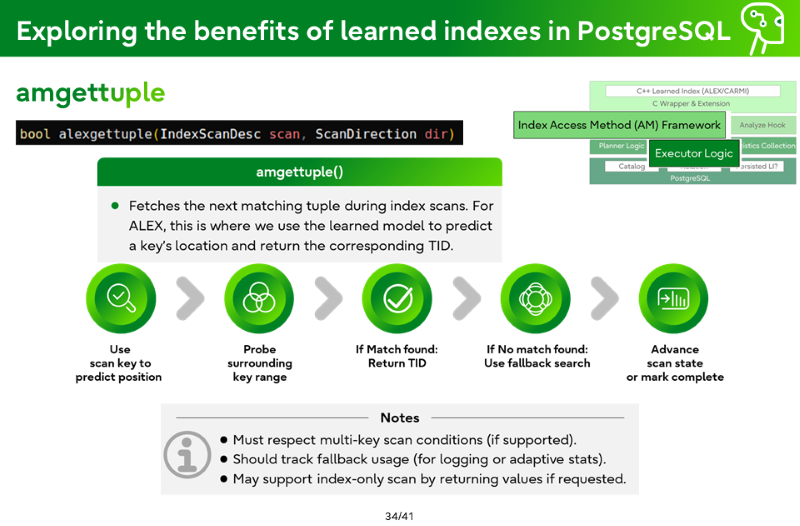
amgettuple
amgettuple()
Fetches the next matching tuple during index scans. For ALEX, this is where we use the learned model to predict a key’s location and return the corresponding TID.
Use scan key to predict position
Probe surrounding key range
If Match found: Return TID
If No match found: Use fallback search
Advance scan state or mark complete
Notes
Must respect multi-key scan conditions (if supported).
Should track fallback usage (for logging or adaptive stats).
May support index-only scan by returning values if requested.
amendscan
ambeginscan()
Initialises the index scan and prepares the scan state before the executor begins fetching tuples
amrescan()
Resets the index scan state to prepare for a new execution of the same scan (commonly used in nested loop joins, or repeated subquery evaluations)
amendscan()
Cleans up resources used by an index scan after execution finishes. In ALEX, it ensures proper teardown of any prediction state, segment access structures, or fallback buffers initialized during the scan.
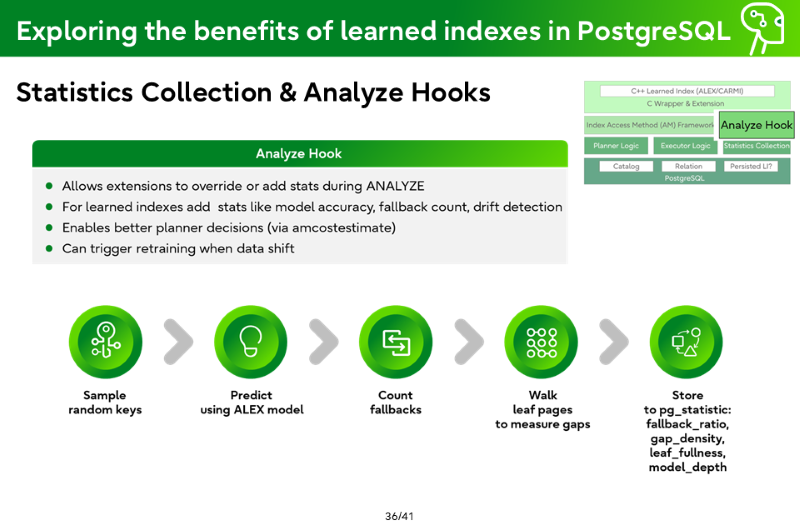
Statistics Collection & Analyze Hooks
Analyze Hook
Allows extensions to override or add stats during ANALYZE
For learned indexes add stats like model accuracy, fallback count, drift detection
Store to pg_statistic: fallback_ratio, gap_density, leaf_fullness, model_depth
Cost estimation calibration
Why calibration is needed
PostgreSQL planner depends heavily on cost estimates.
ALEX lookup = Model evaluation + Local search fallback, not just tree depth.
Wrong costs → Wrong planner decisions.
Key challenges
Different workload behavior:
Point lookups, Range scans, Insert-heavy tables behave differently.
Heavy benchmarking needed to calibrate against B-Trees.
Converting ALEX internals into PostgreSQL-friendly stats manually:
total_slots, gap_density, fallback_ratio
Example 1 (Estimated Cost)
Estimated Cost ≈ Prediction Cost + (Fallback Ratio × Penalty)
Example 2 (Total Slots)
total_slots = Sum of (slots counted on every index page)
ALEX's behavior is dynamic; PostgreSQL expects static statistics.
Calibration must balance optimism (not too cheap) and pessimism (not too expensive).
Crash recovery
Why crash recovery matters
PostgreSQL uses WAL (Write-Ahead Logging) to protect data from crashes
If ALEX is to be a real Access Method, it must properly handle crashes too
Without WAL support, ALEX indexes could become corrupt after a crash
Key challenges
What changes need to be WAL-logged?
Insertions, deletions, model updates, fallback corrections
How to describe ALEX changes in WAL?
WAL records must capture what exactly changed in the ALEX index structure
How to replay ALEX changes?
During crash recovery, the system must rebuild ALEX correctly from WAL
ALEX involves model predictions and structure shifts, not just simple page splits like B-Trees.
WAL logging must be detailed enough to safely recover models and gaps.
Overhead must stay low to avoid slowing down normal inserts and updates
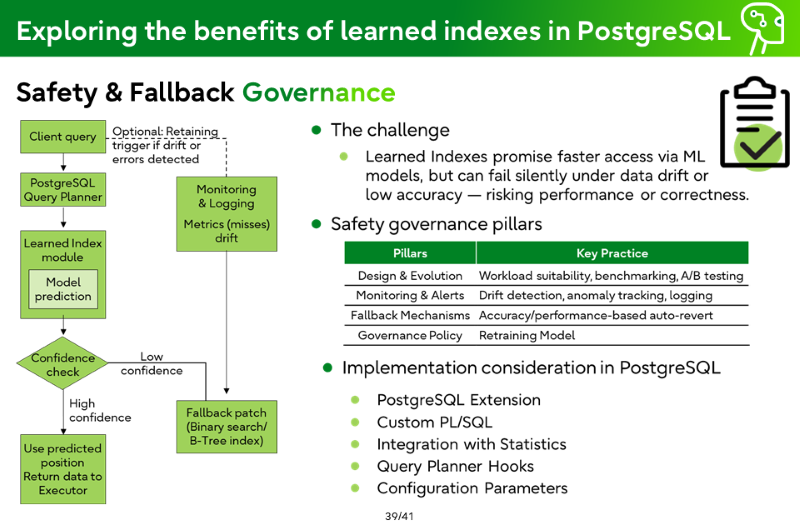
Safety & Fallback Governance
The challenge
Learned Indexes promise faster access via ML models, but can fail silently under data drift or low accuracy — risking performance or correctness.
Safety governance pillars
Pillars
Key pratice
Design & Evolution
Workload suitability, benchmarking, A/B testing
Monitoring & Alerts
Drift detection, anomaly tracking, logging
Fallback Mechanisms
Accuracy/performance-based auto-revert
Governance Policy
Retraining Model
Implementation consideration in PostgreSQL
PostgreSQL Extension
Custom PL/SQL
Integration with Statistics
Query Planner Hooks
Configuration Parameters
Where are we at now?
Our conclusion so far
Without creating our own version of an adaptive learned index specific to PostgreSQL, effective integration that respects PostgreSQL’s architectural design principles does not seem possible as of now
Existing studies that focus on disk pages and have progressed beyond theory to prototypes, don’t outperform B+Tree indexes for most workloads, indicating the effort required to implement an adaptive learned index compatible with the complexities of PostgreSQL's architecture are unlikely to yield significant gains over traditional indexes
Current focus
Writing up a paper on our findings for publication
Investigating and further development of the In-memory ALEX extension for specific use cases like those on slide 27
Investigate whether there is a place for static learned indexes in PostgreSQL use cases
It was a privilege to present at PGConf.dev 2025 in Montreal alongside Nishchay Kothari. Being part of such a vibrant and intellectually rich community of PostgreSQL enthusiasts was both humbling and energizing. The event brought together some of the brightest minds in the database world, and it was inspiring to engage with others who are equally passionate about pushing the boundaries of what PostgreSQL can achieve. We’re grateful for the opportunity to share our research and insights, and to contribute to the ongoing dialogue around innovation in open-source database technologies.
As data volumes continue to grow and workloads become increasingly complex, the relevance of learned indexes in PostgreSQL will only become more pronounced. While traditional indexing methods remain robust and reliable, machine learning-based approaches offer promising avenues for performance optimization, especially in read-heavy and analytical environments. Our work highlights both the potential and the challenges of integrating learned indexes into PostgreSQL’s architecture, and we believe that with continued research and community collaboration, these techniques will evolve from experimental to essential. The journey is just beginning, and we’re excited to see how the PostgreSQL ecosystem embraces this next frontier in intelligent indexing.
Gary Evans heads the Center of Excellence team at Fujitsu Software, providing expert services for customers in relation to PostgreSQL and Fujitsu Enterprise Postgres. He previously worked in IBM, Cable and Wireless based in London and the Inland Revenue Department of New Zealand, before joining Fujitsu. With over 15 years’ experience in database technology, Gary appreciates the value of data and how to make it accessible across your organization. Gary loves working with organizations to create great outcomes through tailored data services and software.
Technical Consultant, Fujitsu Enterprise Postgres Center of Excellence
Nishchay Kothari is an outstanding technical consultant with over 13 years of expertise in relational database management systems (RDBMS). Nishchay has experience with a wide range of database technologies, including PostgreSQL, SQL Server, and Oracle. Nishchay has positioned himself as a go-to resource for organizations wanting to optimize their database infrastructure and architectural solutions driven by his passion for addressing complicated technological challenges.




 Our talk delved into both the theoretical foundations of learned indexes and the practical challenges and considerations involved in integrating them with PostgreSQL’s extensible indexing framework.
Our talk delved into both the theoretical foundations of learned indexes and the practical challenges and considerations involved in integrating them with PostgreSQL’s extensible indexing framework. Click to view the slides side by side
Click to view the slides side by side Top to bottomClick to view the slides in vertical orientation
Top to bottomClick to view the slides in vertical orientation



















 PostgreSQL Insider
PostgreSQL Insider 
