

The flexibility to choose the most appropriate database type for each service is a huge advantage over monolithic architectures. But it can result in serious problems.
Why micro-services?
The micro-services architecture is increasingly being adopted for multiple reasons, including:
- Simplified scaling of large monolithic architectures
- Improved development and delivery of applications due to less complexity and resource contention when working on individual services
- Increased reliability of overall systems, because a service can fail without impacting the rest of the system
- Ability to easily bring failed services back online
- Ability to keep up-to-date with latest technologies by simply changing frameworks and infrastructure
While a micro-services architecture provides many benefits around system development, management, and deployment, it can also increase the complexity of handling data.
One data persistence question that arises with a micro-services architecture is whether to take a polyglot or multi-model approach - there are a number of advantages for both approaches.
Polyglot persistence
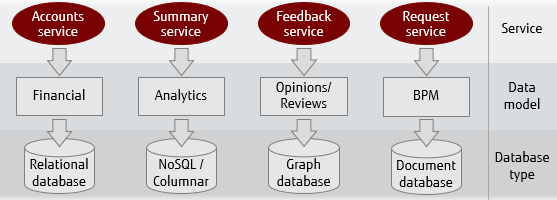
Polyglot persistence has been around for almost a decade now and recommends that each data model is stored in a database type (RDBMS, columnar, graph, etc.) that is best suited for that specific model. The illustration below shows an example of different data models being stored in different database types.
This type of persistence has the recognised benefit of enabling separate teams to work on individual services and be free to choose the most appropriate persistence technology for the data, functionality, and team's expertise.
Unfortunately, there are also a number of potential drawbacks with choosing the polyglot persistence approach:
- Cost associated with maintaining and supporting multiple database technologies. This can be quite excessive as it is not just the cost of licensing products, but also of support, added hardware, and additional training.
- Complexity of the overall system may increase and impact on operational requirements, increasing the risk when providing High Availability across multiple technologies.
- Individual services may require multiple data models to support effective boundary decisions for services, which can greatly increase the complexity of a single service. The resistance to avoid such a scenario can lead to the scope and boundary of services being influenced by types of data, rather than identification of well-defined bounded contexts.
 Multi-model database
Multi-model database
An alternative that avoids many of the above drawbacks is to utilise a multi-model database such as FUJITSU Enterprise Postgres. Multi-model databases support multiple models very well.
- Full-featured Relational Database capabilities
- Support for unstructured and semi-structured data, such as full text, BJSON and XML
- Geospatial support, including geometry, geography, raster, and topology
- Columnar, with in-memory indexing
- Graph
- Time series
FUJITSU Enterprise Postgres features can assist with your micro-services architecture.
Utilising a single technology such as FUJITSU Enterprise Postgres can substantially reduce your operational costs and the complexity of your micro-services system by having to support only one persistence product, being able to support different models for a single service, and utilising a single interface to your data.
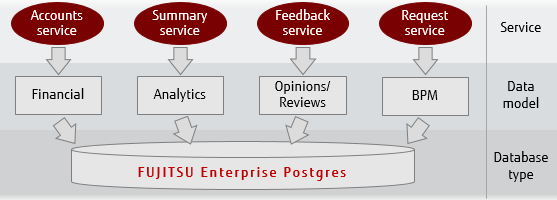
Using a persistence layer that supports multiple models will allow you to focus on identifying boundaries without compromise from having to consider available technologies.
If you’d like to hear how you could be using Fujitsu’s Enterprise PostgreSQL to simplify your micro-services architecture, then contact one of our experts at postgresql@fast.au.fujitsu.com.
