


Typically, when using logical replication PUB/SUB, all data changes from the published tables will be replicated to the appropriate subscribers irrespective of the data origin. With the new ability to filter data in logical replication by its origin, the user can now limit the replication so that only the data changes that originated at the publisher are replicated. This can be used to avoid recursion (infinite replication of the same data) among replication primary nodes. Key to this feature is that WAL records include the origin of the data, which will help the publisher to publish accordingly.
Feature overview
The PostgreSQL command CREATE SUBSCRIPTION has a new parameter - origin - which specifies whether the subscription will request the publisher to send only changes that don't have an associated origin or send changes regardless of origin.
Setting origin to NONE means that the subscription will request the publisher to only send changes that don't have an origin. Setting origin to ANY means that the publisher sends changes regardless of their origin. The default is ANY.
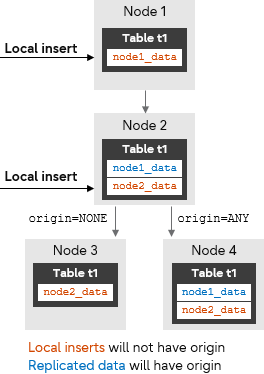
Note that in our example, node 2 will not replicate the row node1_data to node 3, as this data originated from node 1.
Modified CREATE SUBSCRIPTION syntax
Here is a simplified CREATE/ALTER SUBSCRIPTION syntax, highlighting the new origin parameter added for PostgreSQL 16.
CREATE SUBSCRIPTION <sub-name>
CONNECTION 'conninfo'
PUBLICATION <pub-list> [WITH (origin = NONE|ANY)]
ALTER SUBSCRIPTION SET (origin = NONE|ANY)
Example 1
node1=# CREATE SUBSCRIPTION sub_host1_local_data
node1-# CONNECTION 'host=192.168.1.50 port=5432 user=dba1 dbname=salesdb'
node1-# PUBLICATION pub_host1 WITH (origin=NONE);
Example 2
node2=# CREATE SUBSCRIPTION sub_host1_all_data
node2-# CONNECTION 'host=192.168.1.50 port=5432 user=dba1 dbname=salesdb'
node2-# PUBLICATION pub_host1 WITH (origin=ANY);
Filtering when origin=NONE
The walsender process on the publisher will read and decode the WAL file record by record. If origin option is set to NONE, while decoding the WAL records, the output plugin will filter out all the data that have an origin associated.
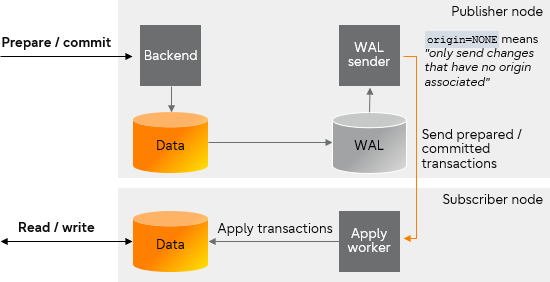
Transactions being filtered by origin=NONE
Replication between primary nodes
Replication between primary nodes is useful for creating a multi-master database environment for replicating write operations performed by any of the member primary nodes. The steps to create replication between primary nodes in various scenarios are given below.
Setting replication between two primary nodes
The following steps demonstrate how to set up replication between two primary nodes (primary1 and primary2) when there is no table data present on both primary nodes.
Note that the user must ensure that no operations are performed on table t1 of nodes primary1 and primary2 until the setup is completed.
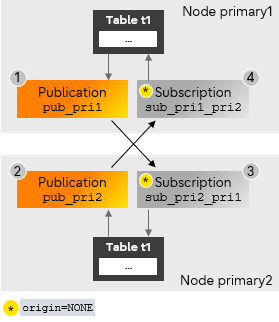
Bi-directional replication between two primary nodes
- Create a publication on node primary1.
primary1=# CREATE PUBLICATION pub_pri1 FOR TABLE t1;
CREATE PUBLICATION - Create a publication on node primary2.
primary2=# CREATE PUBLICATION pub_pri2 FOR TABLE t1;
CREATE PUBLICATION - Create a subscription on primary2 to primary1.
primary2=# CREATE SUBSCRIPTION sub_pri2_pri1
primary2-# CONNECTION 'dbname=foo host=primary1 user=repuser'
primary2-# PUBLICATION pub_pri1 WITH (origin = NONE);
CREATE SUBSCRIPTION - Create a subscription on primary1 to primary2.
primary1=# CREATE SUBSCRIPTION sub_pri1_pri2
primary1-# CONNECTION 'dbname=foo host=primary2 user=repuser'
primary1-# PUBLICATION pub_pri2 WITH (origin = NONE);
CREATE SUBSCRIPTION
At this stage, the replication setup between nodes primary1 and primary2 is complete. Any incremental changes from primary1 will be replicated to primary2, and vice-versa.
We can test drive this setup before we proceed. First, insert some data in the table in node primary1.
primary1=# INSERT INTO t1 VALUES('node1_data1');
INSERT 0 1
Then, read the table in node primary2 - the inserted data will have been replicated.
primary2=# SELECT * FROM t1;
c1
-------------
node1_data1
(1 row)
Now let's do the same test in the opposite direction, from primary2 to primary1. Let's insert some data in primary2, noting that the table already contains data that has been replicated from primary1 above.
primary2=# INSERT INTO t1 VALUES('node2_data1');
INSERT 0 1
primary2=# SELECT * FROM t1;
c1
-------------
node1_data1
node2_data1
(2 rows)
Finally, let's check the table in primary1, and we can see that the data was replicated from primary2.
primary1=# SELECT * FROM t1;
c1
-------------
node1_data1
node2_data1
(2 rows)
Adding a third primary node
The following steps demonstrate adding a new primary node (primary3) to the existing setup when there is no t1 data on any of the primary nodes. This requires creating subscriptions on nodes primary1 and primary2 to replicate the data from primary3, and creating subscriptions on primary3 to replicate data from primary1 and primary2.
These steps assume that the replication between the primary1 and primary2 is already completed.
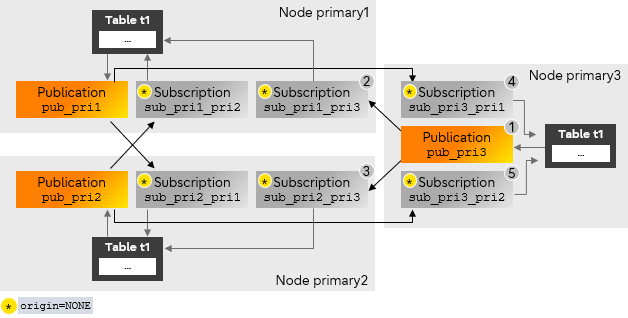
- Create a publication on node primary3.
primary3=# CREATE PUBLICATION pub_pri3 FOR TABLE t1;
CREATE PUBLICATION - Create a subscription on primary1 to primary3.
primary1=# CREATE SUBSCRIPTION sub_pri1_pri3
primary1-# CONNECTION 'dbname=foo host=primary3 user=repuser'
primary1-# PUBLICATION pub_pri3 WITH (origin = NONE);
CREATE SUBSCRIPTION - Create a subscription on primary2 to primary3.
primary2=# CREATE SUBSCRIPTION sub_pri2_pri3
primary2-# CONNECTION 'dbname=foo host=primary3 user=repuser'
primary2-# PUBLICATION pub_pri3 WITH (origin = NONE);
CREATE SUBSCRIPTION - Create a subscription on primary3 to primary1.
primary3=# CREATE SUBSCRIPTION sub_pri3_pri1
primary3-# CONNECTION 'dbname=foo host=primary1 user=repuser'
primary3-# PUBLICATION pub_pri1 WITH (origin = NONE);
CREATE SUBSCRIPTION - Create a subscription on primary3 to primary2.
primary3=# CREATE SUBSCRIPTION sub_pri3_pri2
primary3-# CONNECTION 'dbname=foo host=primary2 user=repuser'
primary3-# PUBLICATION pub_pri2 WITH (origin = NONE);
CREATE SUBSCRIPTION
Now the replication setup between node primary1, primary2, and primary3 is complete. Incremental changes made on any primary node will be replicated to the other two.
Limitations
Our example replication setup has some limitations:
- Adding a new primary node that has existing table data is not supported.
- When using a subscription parameter combination of copy_data=true and origin=NONE, the initial sync table data is copied directly from the publisher, meaning that knowledge of the true origin of that data is not possible.
If the publisher also has subscriptions, then the copied table data might have originated from further upstream. This scenario is detected and a WARNING is logged to the user, but the warning is only an indication of a potential problem - it is the user's responsibility to make the necessary checks to ensure the copied data origins are really as wanted or not.
To identify which tables might potentially include non-local origins (due to other subscriptions created on the publisher) try this SQL query.
SELECT DISTINCT PT.schemaname, PT.tablename
FROM pg_publication_tables PT,
pg_subscription_rel PS
JOIN pg_class C ON (C.oid = PS.srrelid)
JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE N.nspname = PT.schemaname AND
C.relname = PT.tablename AND
PT.pubname IN (<pub-name>);
Caution and notes
When setting up the system bi-directional replication, the user is responsible for designing their schemas in a way to minimize the risk of logical replication conflicts. For a deeper dive on this issue, check the "Conflicts" section in the PostgreSQL documentation for the details of logical replication conflicts.Currently, a few restrictions, or missing functionalities depending on how you see it, apply to logical replication. For further details, check the "Restrictions" section in the PostgreSQL documentation.
Setting up replication between primary nodes requires multiple steps to be performed on various primary nodes. Because not all operations are transactional, the user is advised to take backups. Backups can be taken as described in the "Backup and Restore" section in the PostgreSQL documentation.
And that's a wrap for me
The addition of the origin option is an initial part of supporting multi-master logical replication. This feature adds more flexibility to logical replication. The Fujitsu OSS team along with the community will continue to help enhance and add more capabilities to PostgreSQL logical replication.
For more information on the key points discussed in this post, you can check the following:
- The PostgreSQL page for the CREATE SUBSCRIPTION command describes the syntax and full specification on how to use “origin” - see here.
- The PostgreSQL page "Replication Progress Tracking" explains replication origins in more details than I scoped for in this post, and is a good source for more information.
- PostgreSQL github source code main patch responsible for allowing users to filter logical replication by origin - here.

 PostgreSQL Insider
PostgreSQL Insider 
