PostgreSQL generates an execution plan for a given statement based on statistics.
This article explains how to leverage statistics to control workload fluctuations on your system and maintain performance.
For tuning basics and the role of the planner (optimizer), see the
PostgreSQL Insider article "
Overview of SQL Tuning".
Fixing statistics
In PostgreSQL, the planner (optimizer) refers to relevant statistics based on each SQL query, selects the fastest and lowest-cost method, and creates execution plans. This however may not always be the best possible plan. When statistics are outdated following a large number of update queries, or if statistics are ever-changing, execution plans will be disqualified. As a result, responses may fluctuate or there is a potential risk of temporary low throughput.
As a countermeasure, tuning can be applied using pg_dbms_stats to fix (lock) statistics so that the fixed statistics are always used.
What is pg_dbms_stats
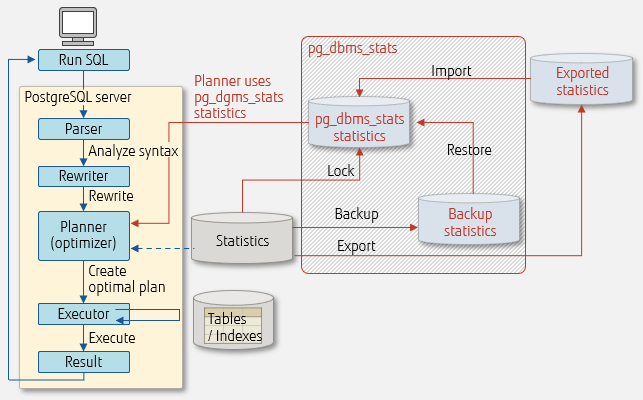
pg_dbms_stats is an extension that manages statistics and indirectly controls execution plans. It runs on Linux, Windows, and Solaris. By using pg_dbms_stats to lock the statistics, users can avoid the disadvantages of PostgreSQL planner (optimizer) selecting an inappropriate execution plan.
pg_dbms_stats has the following features.
| Backup |
Back up current statistics. |
| Restore |
Restore and lock the statistical information. |
| Purge |
Delete all unnecessary backups collectively. |
| Lock |
Lock statistics so that the current execution plan continues to be selected. |
| Unlock |
Unlock the statistics (per object). |
| Clean up |
Release the lock on statistics (collectively delete all unused statistics). |
| Export |
Output the current statistics to an external file (binary format). |
| Import |
Read the statistics from an external file created by the export feature and lock the statistics. |
The mechanism of pg_dbms_stats is illustrated below.
Usage and update lifecycle of pg_dbms_stats
Note
- For specifications of pg_dbms_stats, refer to the extension's GitHub repository here.
- pg_dbms_stats is a powerful tool, but there are points that require attention. We will come back to later in this article ("Notes on pg_dbms_stats"). Be sure to read thoroughly before use.
Using pg_dbms_stats
Let's take a look at how to lock statistics with pg_dbms_stats. The following systems and operations are assumed for this example.
- The system does not allow sudden degradation in response, so the execution of VACUUM and ANALYZE is controlled by the administrator, not by autovacuum.
- The target table is frequently accessed, and data volume varies greatly. Statistics update by ANALYZE is often untimely. Therefore, we will lock the statistics in order to stabilize the response.
This example uses PostgreSQL 11.1 and pg_dbms_stats 1.3.11.
Preparing
To use pg_dbms_stats, first obtain and install this additional module from their public site. Then prepare as follows.
- Start PostgreSQL and execute CREATE EXTENSION for the database that will use this feature.
The target database in this example is “mydb”.
$ psql -d mydb -c "CREATE EXTENSION pg_dbms_stats;"
- Add pg_dbms_stats to shared_preload_libraries in postgresql.conf.
shared_preload_libraries = 'pg_dbms_stats'
- Restart PostgreSQL.
Backing up statistics
Back up statistics when a fast and stable response was gained for a search in a table with indexes. It is assumed that the emp table has been created.
- Confirm the structure and number of data items of the emp table.
mydb=# \d emp;
Table "public.emp"
Column | Type | Collation | Nullable | Default
----------+------------+-----------+----------+---------
empno | integer | | not null |
name | text | | |
age | integer | | |
deptno | integer | | |
salary | integer | | |
Index:
"emp_pkey" PRIMARY KEY, btree (empno) 1
"emp_age_index" btree (age) 2
mydb=# SELECT COUNT(*) FROM emp;
count
------
2000
(1 row)
1An index (primary key) called “emp_pkey” is set in the column “empno” of the emp table.
2An index called “emp_age_index” is set in the column “age” of the emp table.
- Use ANALYZE to update the statistics and check the execution plan of the target SQL.
mydb=# ANALYZE;
ANALYZE
mydb=# EXPLAIN ANALYZE SELECT * FROM emp WHERE age BETWEEN 30 AND 39;
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on emp 1 (cost=18.99..41.82 rows=655 width=22)
(actual time=0.071..1.086 rows=656 loops=1)
Recheck Cond: ((age >= 30) AND (age <= 39))
Heap Blocks: exact=8
-> Bitmap Index Scan on empage_index 1 (cost=0.00..18.83 rows=655 width=0)
(actual time=0.058..0.059 rows=656 loops=1)
Index Cond: ((age >= 30) AND (age <= 39))
Planning Time: 0.148 ms
Execution Time: 2.199 ms
(7 rows)
1You can see that Bitmap Scan is selected for the emp table.
Note
You must use ANALYZE to obtain statistics at least once before backup. Execution plans cannot be controlled when a backup or lock is executed without statistics.
- As a result of the steps above, we can conclude that the response was fast and stable when Bitmap Scan was selected for the execution plan, so we will back up statistics for this.
We will back up in units of databases - use dbms_stats.backup_database_stats() and specify "Bitmap Scan for emp" as its comment.
mydb=# SELECT dbms_stats.backup_database_stats ('Bitmap Scan for emp');
backup_database_stats
-----------------------
1
(1 row)
- Check the backup ID in dbms_stats.backup_history, which stores current backup information.
The dbms_stats.backup_history table is created when pg_dbms_stats is installed, and stores backup information such as backup IDs and timestamps.
mydb=# SELECT * FROM dbms_stats.backup_history;
id | time | unit | comment
----+------------------------------+------+--------------------
11| 2019-07-08 19:24:11.48549+09 | d2 | Bitmap Scan for emp
(1 row)
1The backup ID is "1". Numbering starts from 1 and is increased chronologically when backup is obtained.
2"d" indicates that the backup is performed in units of databases.
Note
Backup can be specified in units of the following objects:
- dbms_stats.backup_database_stats()
- dbms_stats.backup_schema_stats()
- dbms_stats.backup_table_stats()
- dbms_stats.backup_column_stats()
When listing the information in dbms_stats_backup_history, "unit" shows the initial letter of each object.
mydb=# SELECT * FROM dbms_stats.backup_history;
id | time | unit | comment
---+-------------------------------+------+---------------------
1 | 2019-07-08 19:24:11.48549+09 | d | Bitmap Scan for emp
2 | 2019-07-09 13:23:34.274064+09 | s | Index Scan_sc
3 | 2019-07-10 15:25:32.942122+09 | t | Index Scan_tbl
4 | 2019-07-11 17:27:47.453239+09 | c | Index Scan_aid
(4 rows)
Locking statistics using restore
Use restore to lock the statistical information that has been backed up.
- First, let's deliberately unstabilize the execution plan.
Start by deleting 500 records from the emp table. When you update the statistics with ANALYZE, Seq Scan is selected for the emp table. Next, add 2,000 records to the data in the emp table. Check the execution plan of the target SQL without updating the statistics.
Here, we are simulating a case where there was a data search request immediately after a large amount of data had been added, and statistics update by ANALYZE did not occur in time.
mydb=# EXPLAIN ANALYZE SELECT * FROM emp WHERE a ge BETWEEN 30 AND 39;
QUERY PLAN
-------------------------------------------------------------------------
Seq Scan on emp1 (cost=0.00..62.81 rows=8642a width=22)
(actual time=0.020..4.042 rows=11482b loops=1)
Filter: ((age >= 30) AND (age <= 39))
Rows Removed by Filter: 2352
Planning Time: 0.334 ms
Execution Time: 6.962 ms
(5 rows)
1Seq Scan is selected for the emp table.
2Since the statistics have not been updated, there is a large difference between the estimated value (a) and the actual value (b) for the emp table.
- Restore and lock with the restore feature so that the statistics of Bitmap Scan that has been backed up (as described in "Backing up statistics" above) is selected.
To restore the backup statistics (Bitmap Scan) execute dbms_stats.restore_stats, specifying the backup_history table id "1".
mydb=# SELECT dbms_stats.restore_stats(1);
restore_stats
-------------------------
emp
emp_age_index
emp_pkey
(3 rows)
Note
Restore can be performed in either method below - select the one according to your purpose.
Specifying a backup ID
- dbms_stats.restore_stats()
Specifying a timestamp
- dbms_stats.restore_database_stats()
- dbms_stats.restore_schema_stats()
- dbms_stats.restore_table_stats()
- dbms_stats.restore_column_stats()
- Check the execution plan for the target SQL.
mydb=# EXPLAIN ANALYZE SELECT * FROM emp WHERE age BETWEEN 30 AND 39;
QUERY PLAN
-------------------------------------------------------------------------------------
Bitmap Heap Scan on emp1 (cost=18.99..41.82 rows=6552a width=22)
(actual time=0.115..1.970 rows=11482b loops=1)
Recheck Cond: ((age > 30) AND (age <= 39))
Heap Blocks: exact=17
-> Bitmap Index Scan on emp_age_index1 (cost=0.00..18.83 rows=6552a width=0)
(actual time=0.094..0.096 rows=11482b loops=1)
Index_Cond: ((age >= 30) AND (age <= 39))
Planning Time: 0.188 ms
Execution Time: 3.776 ms3
(7 rows)
1Bitmap Scan is selected for the emp table.
2The estimated value (2a) and the actual value (2b) for the emp table are very different.
This is because 2a is the value estimated based on the statistics referenced when Bitmap Scan was selected in step 2 of "
Back up statistics". Note that 2a will not be updated even if ANALYZE is executed here.
3The execution time has been reduced by nearly half compared to step 1.
By locking the statistics in this way, changes in the execution plan is avoidable and you can achieve a stable response.
Releasing the locked statistics
If you want to replace your statistics on pg_dbms_stats with the original PostgreSQL statistics, use the unlock feature.
- To unlock, specify dbms_stats.unlock_database_stats().
mydb=# SELECT dbms_stats.unlock_database_stats();
unlock_database_stats
-------------------------
emp
emp_pkey
emp_age_index
(3 rows)
- Execute VACUUM ANALYZE, and check the execution plan of the target SQL.
mydb=# EXPLAIN ANALYZE SELECT * FROM emp WHERE age BETWEEN 30 AND 39;
QUERY PLAN
--------------------------------------------------------------------------
Bitmap Heap Scan on emp1 (cost=32.05..75.27 rows=11482a width=23)
(actual time=0.080..1.877 rows=11482b loops=1)
Recheck Cond: ((age >= 30) AND (age <= 39))
Heap Blocks: exact=14
-> Bitmap Index Scan on emp_age_index1 (cost=0.00..31.76 rows=11482a width=0)
(actual time=0.067..0.069 rows=11482b loops=1)
Index Cond: ((age >= 30) AND (age <= 39))
Planning Time: 0.317 ms
Execution Time: 3.659 ms
(7 rows)
aBitmap Scan is selected, because the statistics were updated before the query was executed. Note that Seq Scan was selected in step 1 of the previous section ("
Locking statistics using restore").
2The estimated value (a) and the actual value (b) for the emp table match, and the statistics have been updated. We can confirm that statistics is now unlocked.
Note
Fujitsu Enterprise Postgres bundles pg_dbms_stats, and it is installed alongside the product, so users do not need to obtain the module separately.
See the extensions bundled with Fujitsu Enterprise Postgres here.
Notes on pg_dbms_stats
Execution plans can be controlled indirectly by using pg_dbms_stats, but there are some points that require attention.
Impact of changes to the table size
When you lock statistics, they remain locked even if the characteristics of the data change such as their size or patterns. You should consider these impacts and review your locks as required.
Precautions when deleting objects
If you no longer need statistics about a certain table or column, use pg_dbms_stats unlock and purge to delete the pg_dbms_stats-specific statistics first. If you delete the object first, use pg_dbms_stats clean to delete the statistics unique to pg_dbms_stats.
In conclusion
pg_dbms_stats is a powerful module for performance tuning. By understanding its features and how to use it, you can make sure you select the method that is optimal for your system and business requirements.
This will allow you to make informed decisions that will enhance the performance and effectiveness of your database, ultimately contributing to the success of your business.







