Tuning databases involves finding bottlenecks that hinder performance or make maintenance more complex, investigating the causes, and resolving them. In this article, we will explain how to tune your PostgreSQL database to make sure it is the best it can be.
What is database tuning
Database tuning aims at optimizing memory usage and maximizing server performance by reducing disk I/O. This can be done at the initial configuration stage according to the system setup and types of operations.
Before deep diving, we will briefly explain memory and disk I/O prerequisites for database tuning.
Memory and disk I/O
When PostgreSQL accesses a database, it first loads the required data from a disk to a shared buffer on shared memory. After that, it reads and writes the data into the shared buffer. If it becomes necessary to access the same data again, disk I/O is reduced by accessing the information already loaded in the shared buffer instead of accessing the disk.
The same applies to the transaction log. The transaction log, which is a record of data updates, is temporarily stored in a transaction buffer in shared memory and then written to a file on disk. The log is written to file either when the transaction is committed or when the transaction log buffer is full.
Working memory is reserved for each backend process to be used for sorting and table joining. If working memory is insufficient, a work file will be created on the disk and disk I/O will occur to the work file.
What is a backend process?
A process created when a connection request is received from a client. SQL is executed within this process.
Memory used in PostgreSQL
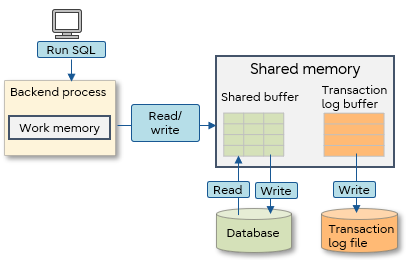
Database tuning means to allocate memory appropriately considering these mechanisms and reduce disk I/O to improve database performance.
Database tuning
You can perform database tuning by adjusting parameters in postgresql.conf. We will explain the parameters that are effective for database tuning by category as below.
| Category |
Parameter |
| Connection |
max_connections |
| Memory |
shared_buffers |
| work_mem |
| maintenance_work_mem |
| Transaction log (WAL) |
wal_buffers |
| max_wal_size |
| checkpoint_timeout |
| Automatic vacuum |
autovacuum_work_mem |
| autovacuum_vacuum_threshold |
| autovacuum_vacuum_scale_factor |
| Lock |
deadlock_timeout |
The parameters and their default values mentioned in this article are used in PostgreSQL 10.
Database instance creation and maintenance is greatly simplified using Fujitsu Enterprise Postgres, Fujitsu's enterprise-enhanced version of PostgreSQL. The 100% OSS-compatible database is bundled with WebAdmin, a GUI-based tool for instance management. For database clusters created using WebAdmin, Fujitsu Enterprise Postgres automatically sets the optimum values for each configuration parameter. If necessary, you can also tune the parameters with WebAdmin.

Parameters
This section describes the parameters that are effective in database tuning.
Connection parameters
- max_connections - Maximum number of clients that can connect to PostgreSQL at the same time.
The default value is 100. Higher values increase memory usage and may affect performance. This is because every time you connect to PostgreSQL, a new server process is started, and you need to tune shared memory and semaphores. It is important to set the appropriate number of connections according to the required task.
Memory parameters
- shared_buffers - Size of the shared buffer.
The default value is relatively small (128 megabytes), so if you use a machine with 1GB or more physical memory, it is recommended to set a value of about 25% of the memory. It is expected that the processing efficiency will be improved by using the shared buffer, however if the buffer size is too large, it may adversely affect the performance because it will take a long time to search the buffer, and the memory area will be compressed, causing disk swap. Therefore, it is necessary to tune the setting values carefully while conducting verification.
As reference, execute the following SQL to confirm the cache hit rate from blks_read (number of blocks read from disk [disk I/O occurrence]) and blks_hit (number of blocks that hit the buffer) in the pg_stat_database view.
SELECT datname,blks_read, blks_hit, round (blks_hit * 100 / (blks_hit + blks_read),2) AS hit_ratio
FROM pg_stat_database WHERE blks_read > 0;
- work_mem - Size of working memory used for sorting and hash table operations when executing queries.
The default value is 4 megabytes. Increasing the work_mem value is expected to improve query performance. However, if the work_mem value is large, the required memory becomes large in proportion to the number of connections and query contents, and there is a possibility that the memory will be exhausted.
Set a value that is at most "(physicalMemSory - shared_buffersValue) / max_connectionsValue" or less. For complex queries, sorting and hashing may occur multiple times within the query. In this case, it is necessary to use memory that is several times as large as the work_mem value, which may lead to performance degradation due to insufficient memory, so caution should be taken.
- maintenance_work_mem - Size of working memory used for maintenance operations such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY.
The default value is 64 MB. By increasing this working memory, manual vacuuming and indexing can be performed at high speed.

Transaction log (WAL) parameters
We will explain checkpoints first, as they are a prerequisite to understanding parameters related to transaction logs.
PostgreSQL does not write the updated data in the shared buffer to a disk frequently. However, it writes transaction logs to the transaction log file on the disk to ensure data reliability, in case the shared buffer data is lost in case of failure. The issue is that transaction logs cannot be accumulated indefinitely, so it is necessary to control them at some point - this timing is called checkpoint.
At a checkpoint, the updated data in the shared buffer is recorded to the disk, and unnecessary transaction logs are deleted. Since they require disk writes, frequent checkpoints may cause performance degradation, which makes the interval between checkpoints very important. This can be configured with the max_wal_size and checkpoint_timeout parameters. When either of these thresholds is reached, a checkpoint occurs and all updated data in the shared buffer is written to the disk. If you set a small value, disk I/O will occur frequently. On the other hand, if the value is set too high, it may increase the recovery time, because the updated data required for recovery is kept as a transaction log.
- wal_buffers - Size of the transaction log buffer.
The default value is 1/32 of the value of shared_buffers. Transaction logs are written to the transaction log file on a disk each time a transaction commits, so there is no need to set a value higher than necessary. However, the transaction log buffer may become full with unwritten transaction logs, such as when transactions that frequently update data are executed or when many transactions are executed simultaneously. In such a case, the disk access concentration occurs because all the accumulated transaction logs are written to the disk without waiting for the transaction to be committed, so consider increasing the wal_buffers value.
- max_wal_size - Size of the transaction log that triggers checkpoint processing.
The default value is 1 gigabyte. When the transaction log of the size specified here is written to the transaction log file, checkpoint processing is performed. If the following message is output in the log message, it means that checkpoints occur frequently, so consider increasing the max_wal_size value.
LOG: checkpoints are occurring too frequently (19 seconds apart)
HINT: Consider increasing the configuration parameter "max_wal_size"
- checkpoint_timeout - The interval of checkpoint processing in time.
The default value is 5 minutes. The default value is short, so it is recommended to set 30 minutes as the initial value. As described above, recovery time must be taken into consideration when setting the value. However, if the data is not updated frequently, the transaction log amount will be small, so you can set a relatively long value in that case.
Parameters related to automatic vacuum
In PostgreSQL, when data is updated or deleted, it initially remains in the original table location, but with a delete flag set. The updated data will be added as a new data item at the end of the table. This mechanism is called write-once architecture.
By adopting this architecture, PostgreSQL enables MVCC (MultiVersion Concurrency Control) that can update and reference the same data at the same time. If no transaction refers to the original data with the delete flag, it means that the data space is unnecessary. When such unnecessary space increases, the file size also increases, and it becomes difficult to cache in the shared memory, which results in performance degradation due to the increase of disk access.
To avoid the file from growing indefinitely, this unnecessary space is changed to a reusable state by a process called vacuuming.
MVCC and vacuum
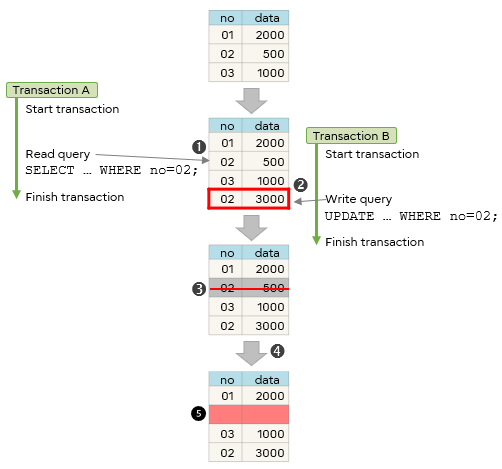
The vacuum process is normally performed automatically by the autovacuum feature (the autovacuum parameter in postgresql.conf is enabled by default), but you can adjust its parameters to make it even more effective.
- autovacuum_work_mem - Size of the working memory for autovacuum.
The default value follows the setting of maintenance_work_mem. Insufficient working memory results in longer vacuum times and affects performance. Refer to the autovacuum execution log, and if the index scan is 2 or more, it is effective to increase the memory. The log output for the automatic vacuum execution is set by the log_autovacuum_min_duration parameter in postgresql.conf.
Example of log output when executing automatic vacuum
Log: automatic vacuum of table "mydb.public.sales": index scans: 2
- autovacuum_vacuum_threshold / autovacuum_vacuum_scale_factor - Number of updated rows used as a threshold to determine whether to perform autovacuum, and percentage of updated data used as a threshold to determine whether to perform autovacuum, respectively.
- The default value of autovacuum_vacuum_threshold is 50 lines, and the default value of autovacuum_vacuum_scale_factor is 20%, which means that 20% of the table is no longer needed.
Autovacuum is executed when the number of updated rows in the table exceeds the result of the formula below:
autovacuum_vacuum_thresholdValue + autovacuum_vacuum_scale_factorValue x numberOfRowsInTable
Since autovacuum_vacuum_scale_factor specifies a percentage, the number of rows in the unnecessary space to be vacuumed is dependent on the total number of rows in the table. The more rows in the table, the longer the vacuum processing takes. For a table with a large number of rows, it is efficient to set a small value for autovacuum_vacuum_scale_factor so that vacuuming is performed less frequently. However, note that setting the parameters in postgresql.conf targets all tables. It is recommended to use the ALTER TABLE statement for each table so that the timing of vacuum processing can be controlled for each table.
Parameters related to lock
In PostgreSQL, when multiple transactions update the same data and a lock wait occurs, processing to detect whether it is a deadlock (a lock that will never be released) is executed. The deadlock detection puts a load on the database and may cause performance degradation. Therefore, set a waiting time for starting deadlock detection.
In this article, we explained database tuning. Perform appropriate parameter tuning according to the system scale and operation requirements so that performance does not deteriorate.







