In this article, we will explain tuning using hint phrases of pg_hint_plan to control execution plans.
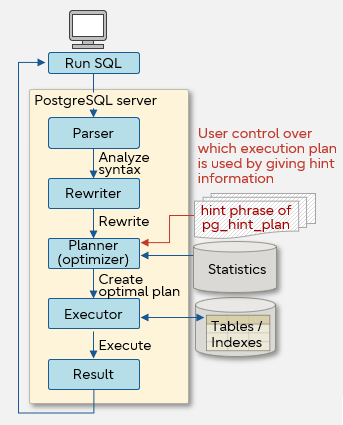
Controlling execution plans
In PostgreSQL, the planner (optimizer) looks up relevant statistics based on the SQL query, selects the fastest and lowest-cost method, and creates an execution plan. However, this may not always be the optimal plan, especially when the statistics are stale after a large number of update queries or if statistics change too often.
Furthermore, in core business systems, stability is critical and is often prioritized over performance. In such cases, you would want to avoid ever-changing execution plans and rather take control by setting consistent plans.
Hint phrases can be set in queries which explicitly specify access methods like table scans and joins. This forces the planner (optimizer) to output stable execution plans.
This article will describe how to tune your database system by leveraging hint phrases of pg_hint_plan, one of the tools available for PostgreSQL.
What is pg_hint_plan?
pg_hint_plan is a tool that allows the user to control execution plans in PostgreSQL by setting hint phrases. pg_hint_plan runs on Linux, Windows, and Solaris. The types of hint phrases that can be specified in pg_hint_plan are as follows.
- How to scan when querying tables
- The order of joining multiple tables
- How to join tables
- Correction of the estimated number of rows for table joins
- Forced or forbidden execution of parallel query
- Changes of PostgreSQL parameters only during SQL execution
Control execution plans with pg_hint_plan
Reference
- For specifications of pg_hint_plan, refer to the tool's repository webpage in GitHub.
- pg_hint_plan is a useful feature, but there are some points that require your attention. Read "Notes on pg_hint_plan" below before using.
Using pg_hint_plan
Let's see step by step how to set hint phrases using pg_hint_plan. This example uses PostgreSQL 11.1 and pg_hint_plan 11.1.3.2.
Preparation
To use pg_hint_plan, you need to obtain it from GitHub and install it, and then make the following preparations.
- Start PostgreSQL and execute CREATE EXTENSION for the database that you want to use pg_hint_plan. In this example, we call the target database "mydb".
$ psql -d mydb -c "CREATE EXTENSION pg_hint_plan;"
- Add pg_hint_plan to the shared_preload_libraries parameter in postgresql.conf.
shared_preload_libraries = 'pg_hint_plan'
- Restart PostgreSQL.
Setting hint phrases
This section describes a tuning example that uses hint phrases to specify the search process of tables with an index. It assumes that the emp and dept tables already exist.
- Check the configurations of the emp and dept tables.
mydb=# \d emp;
Table "public.emp"
Column | Type | Collation | Nullable | Default
-------+---------+-----------+----------+--------
empno | integer | | not null |
name | text | | |
age | integer | | |
deptno | integer | | |
salary | integer | | |
Index
"emp_pkey" PRIMARY KEY, btree (empno) 1
"emp_age_index" btree (age) 2
mydb=# \d dept;
Table "public.dept"
Column | Type | Collation | Nullable | Default
-------+---------+-----------+----------+--------
deptno | integer | | |
name | text | | |
Index
"dept_deptno_index" UNIQUE, btree (deptno) 3
1 An index (primary key) called emp_pkey is set in the column empno of the emp table.
2 An index called emp_age_index is set in the column age of the emp table.
3 An index (unique constraint) called dept_deptno_index is set in the column deptno of the dept table.
- Check the number of rows in emp and dept tables.
mydb=# SELECT COUNT(*) FROM emp;
count
-------
2000
(1 row)
mydb=# SELECT COUNT(*) FROM dept;
count
------
30
(1 row)
- Use ANALYZE (SQL command) to update the statistics and specify conditions to search data.
mydb=# ANALYZE;
ANALYZE
mydb=# EXPLAIN ANALYZE WITH age30 as (SELECT * FROM emp WHERE age BETWEEN 30 AND 39)
SELECT * FROM age30, dept WHERE age30.deptno = dept.deptno ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Hash Join (cost=43.49..58.34 rows=98 width=58) (actual time=0.260..5.645 rows=656 loops=1)
Hash Cond: (age30.deptno = dept.deptno)
CTE age30
-> Bitmap Heap Scan on emp 1(cost=18.99..41.82 rows=655 width=22)
(actual time=0.064..1.158 rows=656 a loops=1)
Recheck Cond: ((age >= 30) AND (age <= 39))
Heap Blocks: exact=8
-> Bitmap Index Scan on emp_age_index (cost=0.00..18.83 rows=655 width=0)
(actual time=0.049..0.051 rows=656 a loops=1)
Index Cond: ((age >= 30) AND (age <= 39))
-> CIE Scan on age30 (cost=0.00..13.10 rows=655 width=48) (actual time=0.070..3.268 rows=656 loops=1)
-> Hash (cost=1.30..1.30 rows=30 width=10) (actual time=0.155..0.156 rows=30 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> Seq Scan on dept 2(cost=0.00..1.30 rows=30 width=10) (actual time=0.009..0.058 rows=30 b loops=1)
Planning Time: 0.650 ms 2
Execution Time: 6.842 ms
(14 rows)
1 Bitmap Scan was selected for the emp table
2 Seq Scan was selected for the dept table
a Number of rows processed by Bitmap Scan for the emp table
b Number of rows processed by Seq Scan for the dept table
The following are typical scanning methods using indexes. The circled numbers indicate the order of access to the index and the table.
| Scanning method |
Description |
Index Scan
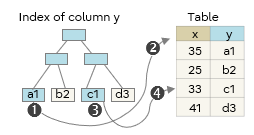 |
Randomly accesses the index and the table alternately.
This is an effective method when you want to access specific data or when the number of items to be retrieved using WHERE is small.
|
Bitmap Scan
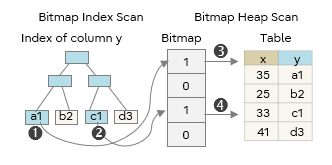 |
The candidate rows from the indexes are bitmapped in memory, and only the candidate rows from tables are acquired.
After making a bitmap, the table is accessed sequentially, skipping non-candidate rows. This is an effective method when the number of items to be retrieved is moderate.
|
Index only scan
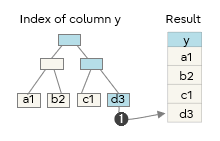 |
Only accesses the indexes and returns the result for the applicable index.
This is a useful method when you only need information for the indexed data.
|
- Now we will change the execution plan using hint phrases.
Set the hint phrase so that Index Scan using emp_age_index of the emp table is selected. Specify the hint phrase in the format /*+ <hint phrase> */.
mydb=# EXPLAIN ANALYZE WITH /*+ IndexScan (emp emp_age_index) */
age30 as (SELECT * FROM emp WHERE age BETWEEN 30 AND 39)
SELECT * FROM age30, dept WHERE age30.deptno = dept.deptno;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Hash Join (cost=46.65..61.50 rows=98 width=58) (actual time=0.240..6.309 rows=656 loops=1)
Hash Cond: (age30.deptno = dept.deptno)
CTE age30
-> Index Scan using emp_age_index on emp 1 (cost=0.28..44.98 rows=655 width=22)
(actual time=0.031..1.363 rows=656 loops=1)
Index Cond: ((age >= 30) AND (age <= 39))
-> CTE Scan on age30 (cost=0.00..13.10 rows=655 width=48) (actual time=0.038..3.766 rows=656 loops=1)
-> Hash (cost=1.30..1.30 rows=30 width=10) (actual time=0.181..0.183 rows=30 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> Seq Scan on dept (cost=0.00..1.30 rows=30 width=10) (actual time=0.011..0.076 rows=30 loops=1)
Planning Time: 0.406 ms
Execution Time: 7.517 ms
(11 rows)
1 Index Scan was selected for the emp table, as specified in the hint phrase.
In this way, pg_hint_plan can be used to deliberately control the behavior of PostgreSQL.
Note
The methods for specifying the hint phrase in pg_hint_plan are as follows:
- By comment: Write a hint specifically in a SQL block comment in the application.
- In a table: Register the hint in a table for hints. You can adjust the hints without changing the application.
The types of hint phrases that can be specified in pg_hint_plan and typical hint phrase formats are shown below.
- Scan method for querying tables:
SeqScan(table), IndexScan(table [index…])
- The order of joining multiple tables:
Leading(table table [table…])
- How to join tables:
NestLoop(table table [table…]), HashJoin(table table [table…])
- Correction of estimated number of rows for joins:
Rows(table table [table…] correction)
- Forced or forbidden execution of parallel query:
Parallel(table numberOfWorkers [hard|soft])
- Changes of PostgreSQL parameters only during SQL execution:
Set(GUC-parameterValue)
If the table has a different name in the SQL statement, specify the alias in the hint phrase.
You can specify multiple hint phrases in one query. An example is shown below.
Name the emp table differently (for example "ta" and "tb"), then specify hint phrases separately.

Note
Fujitsu Enterprise Postgres has been bundling pg_hint_plan since version 9.5. Because pg_hint_plan is bundled with the product, it is not necessary to acquire it separately.
Notes on pg_hint_plan
pg_hint_plan is a convenient feature that allows the user to control execution plans, but the following points should be noted.
- Impact of table data size changes
When a hint phrase is set, the execution plan remains fixed. This means, the execution plan that was optimal when the data size of the table was small may no longer be the best plan after growth of the table data size.
- Impact of changing the SQL statement
If you are changing the SQL for which a hint phrase is set, verify the validity of the hint phrase again and review it. This for example may happen during an application update.
- Impact of major version upgrade of PostgreSQL
Using a hint phrase from the previous version as is in a new PostgreSQL version may cause performance degradation. This is because the planner (optimizer) may improve in a major version upgrade of PostgreSQL.
pg_hint_plan is effective in tuning one-time SQL with fixed business requirements, verifying how the execution plan works, or stabilizing performance. It is a powerful tool when employed accordingly to each scenario.
We hope this article helped you to understand the features and the use of pg_hint_plan as one of the means of performance tuning. Remember to always select the method that best suits your system and business requirements.







