Streaming replication setup might come in hand if your server fails, as it can provide a backup plan just when needed. We know that any server can fail, and it is a must to be prepared for the worst-case scenario. This article focuses on streaming replication failover and recovery, which are the two inevitable steps to achieve stable and continuous operation.
Streaming replication failover
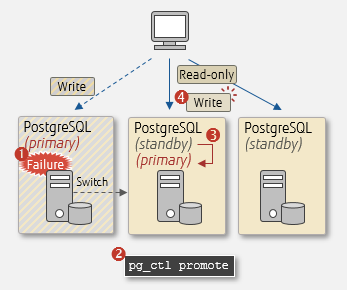
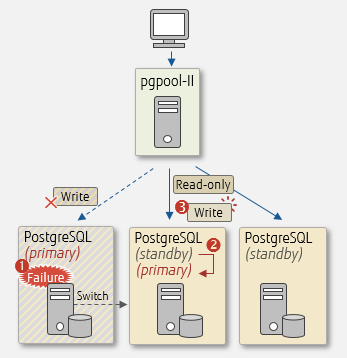
With this setup, business can continue even if the primary server fails, by switching to the standby server. PostgreSQL does not have features for error detection and automatic switching. A mechanism for detecting an abnormality and a script for promoting the standby server ('pg_ctl promote') needs to be incorporated. Alternatively, cluster software such as pgpool-II can be used, with its error detection and automatic switching features.
Manual switch using pg_ctl
Automatic switch using pgpool-II
Streaming replication recovery
The recovery actions to take differ depending on which server, primary or standby, is down. The following describes measures for each scenario assuming that synchronous replication is used.
If the primary server fails
If the primary server fails, you need to rebuild it as a standby server. There are various methods to recover the failed server, but two typical methods are described below.
Using database backup
The first method uses database backup (pg_basebackup command). The flow can be summarized as follows:
- Copy the latest database cluster from the new primary server (pg_basebackup command).
- Configure the necessary settings so the failed server works as a standby server.
- Start the failed server.
By doing that, the failed server can be set up as a new standby server. If the database is large, it will take some time to rebuild.
Recovery overview
Recovery with pg_basebackup
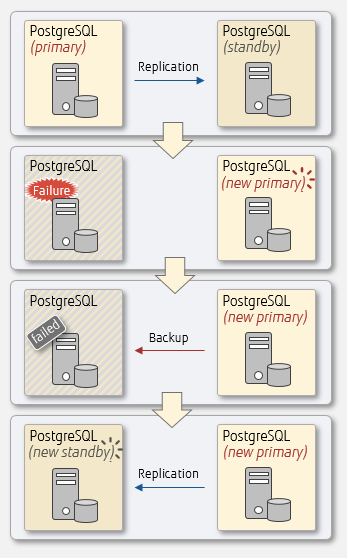
Use the backup to start as a standby server.
Recovery procedure
- Identify the cause of the failure, take corrective actions, and recover the failed server.
- On the failed server, delete the database cluster.
- Execute the pg_basebackup command with the -R option on the failed server to obtain a physical backup from the new primary server.
- Modify recovery.conf on the failed server:
- Set standby_mode=on
- Set application_name in primary_conninfo
- Modify postgresql.conf on the failed server:
- Disable synchronous_standby_names
- Start the failed server – it will become the new standby server.
- Modify postgresql.conf on the new primary server:
- Set synchronous_standby_names to the new standby server.
How to use cluster files
The second method uses cluster files for recovery. This method is possible only if the database on the failed server has not failed due to hardware issues and you can restart the database. The flow can be summarized as below:
- Synchronize the difference between the failed server and the new primary server (using the pg_rewind command).
- Configure the necessary settings so the failed server works as a standby server.
- Start the failed server.
By doing the above, the failed server can be set up as a new standby server. Compared to the pg_basebackup command, the pg_rewind command can rebuild the setup in a relatively short time. However, note that the following conditions need to be met when running pg_rewind:
- The failed server has stopped normally.
- The wal_log_hints parameter in postgresql.conf is enabled, or data checksum is valid when initialising a database cluster with initdb.
Recovery overview
Recovery with pg_rewind
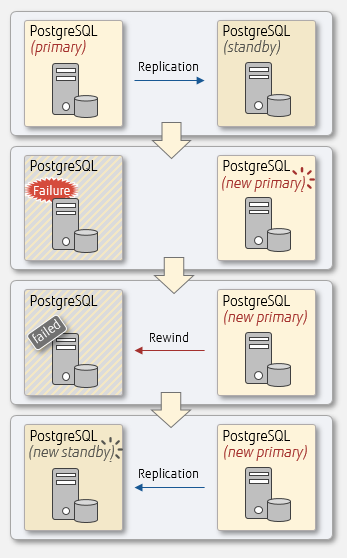
Use pg_rewind to synchronize the failed server with the new primary server.
Recovery procedure
- Identify the cause of the failure, take corrective action, and recover the failed server.
- The failed server must be stopped normally in order to run pg_rewind, so start the failed server and stop it normally.
- Execute the pg_rewind command on the failed server.
- Create recovery.conf on the failed server:
- Set standby_mode=on
- Set recovery_target_timeline=latest
- Set application_name in primary_conninfo
- Modify postgresql.conf on the failed server:
- Disable synchronous_standby_names
- Start the failed server. It becomes a new standby server.
- Modify postgresql.conf on the new primary server:
- Set synchronous_standby_names to the new standby server and reload.
- Make sure that the new standby server and the new primary server have the same timeline IDs.
Timeline IDs can be obtained with pg_controldata.
If a standby server fails
The actions to take when the standby server fails differ depending on whether the standby server was replicated synchronously or asynchronously. The following describes each measure.
If it was replicated synchronously
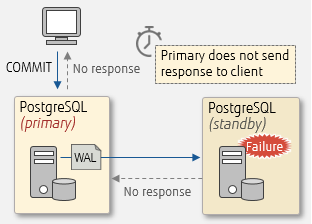
If a standby server fails while replicating synchronously, the primary server will keep waiting for a response and will not be able to send a COMMIT response to the client. Therefore, it will be necessary to disconnect the failed standby server, in order to switch from synchronous replication to asynchronous replication.
Delete the failed server name from synchronous_standby_names in postgresql.conf on the primary server, and reload the file ('pg_ctl reload'). If all standby servers have stopped, empty the synchronous_standby_names parameter and then reload.
To recover the failed server, follow the same recovery procedure for primary server described above.
Failure during synchronous replication
If it was replicated asynchronously
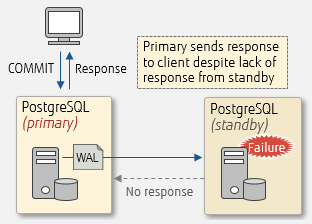
With asynchronous replication, there is no need to edit postgresql.conf or reload the file if a standby server fails. To recover a failed standby server asynchronously replicated, follow the same recovery procedure for primary server described above.
Failure during asynchronous replication
We explain streaming replication and its key configuration points in our article "
What is streaming replication, and how can I set it up?". Check it out if you would like to get a better understanding of how PostgreSQL implements it and how to properly configure.
This article provided an overview of failover and recovery measures available when using PostgreSQL streaming replication, which is very useful to achieve database high availability. FUJITSU Enterprise Postgres offers database multiplexing with attractive features such as error detection and automatic failover.







