In the context of database, replication means creating a copy of a database. With replication, you can build a highly available system that can continue operating even if a failure occurs. In addition, by utilizing the replicated database for processing read-only SQL, more processes can be run in the entire system. On top of that, a database replicated to a remote location can be used for disaster recovery as well.
In PostgreSQL, there are two types of replication features: streaming replication (physical replication) that collectively replicates a database cluster, and logical replication that replicates in units of tables and databases.
In this article, we focus on the mechanism and configuration of streaming replication that replicates a database cluster in batch.
What is streaming replication?
Streaming replication, a standard feature of PostgreSQL, allows the updated information on the primary server to be transferred to the standby server in real time, so that the databases of the primary server and standby server can be kept in sync. The streaming replication features below bring great benefits to your system.
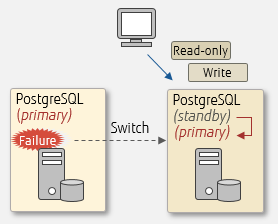
- Failover: When the primary server fails, the standby server can take over the operation.
- Read-only load balancing: Read-only SQL processing can be distributed among multiple servers.
Failover
Read-only load balancing
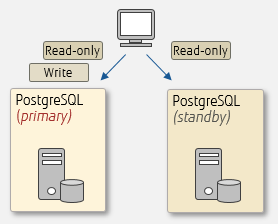
You can process read-only SQL on the standby server to distribute read-only workload. However, PostgreSQL does not have a distribution feature that considers queries and server load. By using the load balancing feature of pgpool-II, an open source extension, read-only queries can be efficiently distributed between the PostgreSQL instance, and workload can be balanced.
Streaming replication mechanism
To understand how streaming replication works, let's take a closer look at what to transfer and how to transfer it.
What is shipped
PostgreSQL saves the updated information of the primary server as a transaction log known as write-ahead log, or WAL, in preparation for crash recovery or rollback. Streaming replication works by transferring, or shipping, the WAL to the standby server in real time, and applying it on the standby server.
WAL transfer
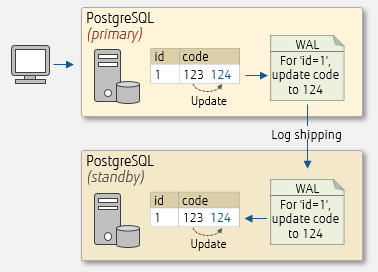
How the WAL is shipped and applied
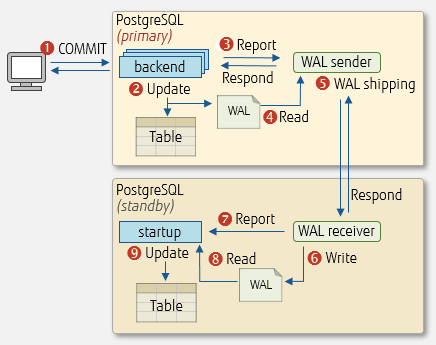
WAL shipping between the primary server and the standby server is performed by the WAL sender process on the primary server to the WAL receiver process on the standby server. These processes are started by setting postgresql.conf and pg_hba.conf parameters – we will discuss them later in this article.
WAL sender/receiver process
Setup
This section describes the setups that can be configured with streaming replication, and extends the discussion to synchronous and asynchronous replications.
Multi-standby setup and cascade setup
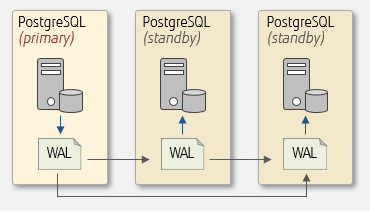
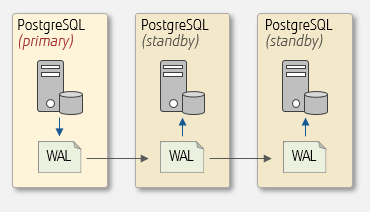
Streaming replication can be built in a 1:N configuration, where only one primary server is configurable, but multiple standby servers can be set up. The configuration that connects (ships WAL from) a primary server to all standby servers is called a multi-standby setup. You can also build a cascade setup where a standby server connects (ships WAL) to another standby server.
Multi-standby setup
Cascade setup
Synchronous replication and asynchronous replication
For streaming replication, you can select either synchronous or asynchronous replication for each standby server. This section describes the characteristics of each, and key points for configuration.
Characteristics of synchronous and asynchronous replications
The difference between synchronous replication and asynchronous replication is whether or not to wait for the response from the standby server before completing the processing on the primary server. Choose the configuration according to your operation, since this affects the response time of SQL processing and high availability.
Synchronous replication
The primary server waits for a response from the standby server before completing a process.
Therefore, the overall response time includes the log shipping time.
Since there is no delay in WAL shipping to the standby server, the data freshness (reliability) of the standby server is improved.
Suitable for failover and read-only load balancing operations.
Asynchronous replication (default)
The primary server completes a process without waiting for a response from the standby server.
Therefore, the overall response time is about the same as when streaming replication is not used.
Since WAL shipping and its application (data update) on the standby server are done asynchronously, the updated result on the primary server may not be immediately available on the standby server.
Depending on the timing of failover, data may be lost.
Suitable for replication to remote areas for disaster recovery.
Synchronous/asynchronous setup (synchronous_standby_names)
Synchronous setup is configured by synchronous_standby_names in postgresql.conf on the primary server. If there are multiple standby servers, you can specify the servers to be synchronized and the order of priority for COMMIT. Standby servers not specified in this parameter will be asynchronous.
Example: 'synchronous_standby_names = FIRST 2 (s1, s2, s3)'
You can also specify the method by which to select synchronous standby servers from a list of servers, such as 'FIRST n (list)' or 'ANY n (list)'. The FIRST keyword specifies that the n first standby servers in list will be synchronous and that transaction commits will wait until their WAL records are replicated to the first n standby servers in list. The ANY keyword specifies a quorum-based synchronous replication and that transaction commits should wait until their WAL records are replicated to at least n standby servers in list.
For example, in an environment using standby servers s1, s2, s3, and s4, setting synchronous_standby_names to 'FIRST 2 (s1, s2, s3') will configure s1 and s2 for synchronous replication, and s3 and s4 for asynchronous replication. The primary server will wait s1 and s2 to complete processing before it commits. If s1 or s2 fails, then s3 changes to synchronous replication.
Setup as
FIRST 2 (s1 ,s2, s3)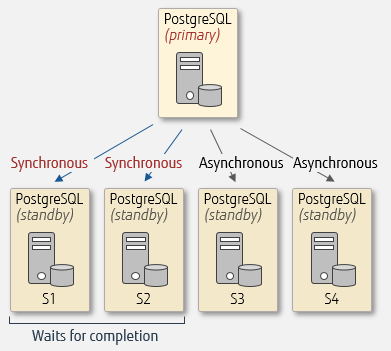
Same setup, after failure of s1
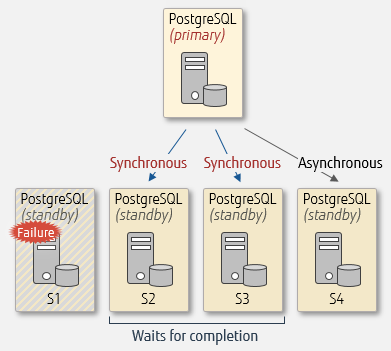
Make sure that the name set in synchronous_standby_names matches the name set in application_name of primary_conninfo in postgresql.conf on the standby server. This parameter is discussed later in this article.
Setting the synchronization level
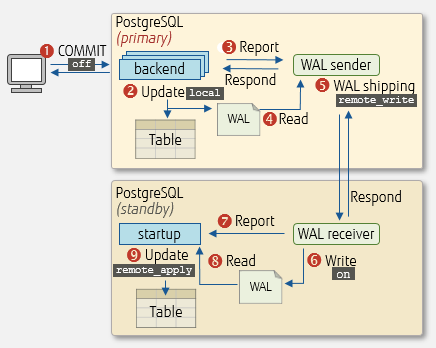
To set the synchronization level of the standby server, set synchronous_commit in postgresql.conf on the primary server. This section describes the values that can be set and their overview. The circled numbers in the 'Guaranteed range' column of the table match the numbers in the diagram directly below the table.
| Sync level |
Set value |
Overview |
Guaranteed range |
| Full synchronous |
remote_apply |
Commits wait until after the WAL is replicated to the standby servers and the updated data on the standby server is available to read-only queries. It is fully assured that the data is in sync, so it is well suited for load balancing of read-only workloads that require data freshness. |
1 to 9 |
| Synchronous |
on (default) |
Commits wait until after the WAL is replicated to the standby servers. This setting achieves the best balance between performance and reliability. |
1 to 6 |
| Semi-synchronous |
remote_write |
Commits wait until after WAL has been shipped to the standby servers. |
1 to 5 |
| Asynchronous |
local |
Commits wait until after the WAL write on the primary server is completed. |
1 to 2 |
| Asynchronous |
off |
Commits do not wait for the WAL write on the primary server to complete. This setting is not recommended. |
1 |
Synchronization level
Configuring the primary and standby servers
We list below the parameters required to use the streaming replication feature, setting up synchronous replication and archiving the WAL.
As of PostgreSQL 12, recovery.conf no longer exists, and its parameters have been integrated into postgresql.conf
Settings on the primary server
Set the values below in postgresql.conf and pg_hba.conf on the primary server.
| File name |
Parameter |
Value |
| postgresql.conf |
listen_addresses |
'*' for all available IP interfaces. |
| wal_level |
'replica' (default). |
| max_wal_senders |
numberOfStandbyServers+1.
This value cannot exceed the value set in max_connections. |
| max_connections |
Maximum number of simultaneous connections to the database server.
Set a value greater than max_wal_senders. |
| wal_keep_segments |
Minimum number of file segments to keep in the pg_wal directory.
If you do not want to archive, set a slightly increased value. |
| wal_sender_timeout |
Time to wait before determining that the WAL receiver process is in an abnormal state. |
| synchronous_standby_names |
Standby servers for synchronous replication. No setting is required for asynchronous replication.
Example: 's1' |
| synchronous_commit |
Synchronization level of the standby servers.
Set 'remote_apply' to optimize data freshness and 'on' to maintain performance and reliability. |
| archive_mode |
'on'. |
| archive_command |
Command for archiving the WAL.
Example: 'cp %p /mnt/serv/arch_dir %f' |
| pg_hba.conf |
Set the 'database' column to 'replication'.
Example: host replication someuser 187.168.1.5 passwd |
Settings on the standby server
Set the values below in postgresql.conf on the secondary server.
| File name |
Parameter |
Value |
| postgresql.conf |
hot_standby |
'on' (default) |
| wal_receiver_timeout |
Time to wait before determining that the WAL sender process is in an abnormal state. |
| standby_mode |
'on'. |
| primary_conninfo |
Connection information to the primary server.
Set the same name for application_name and synchronous_standby_names in postgresql.conf on the primary server.
Example: 'host=187.168.1.50 port=5432 user=someuser password=passwd application_name=s1' |
| restore_command |
Set the command to get the WAL archive.
Example: 'scp usr@187.168.1.50:/mnt/serv/arch_dir/%f %p' |
In case the primary server fails, a standby server will be promoted. For this reason, we recommend setting common parameters on the primary and standby servers in advance.







