Enterprise database systems demand high availability - systems should be tolerant of failures and operate stably at all times. Equally important is scalability, so that servers can be added as systems evolve. Response speed and processing capacity need to be maintained even with increased data volume or access.
In this article, we discuss a highly available system setup using pgpool-II, one of PostgreSQL open source extensions. It is one of our solutions to meet both requirements: high availability and scalability.
What is pgpool-II?
pgpool-II is a middleware that can run on Linux and Solaris between applications and databases. Its main features include the following:
| Feature |
Classification |
Explanation |
| Load balancing |
Distributes read-only queries to multiple database servers efficiently, so that more queries can be processed. |
Performance improvement |
| Connection pooling |
Retains/reuses connections to databases to reduce connection overhead and improve performance when reconnection is made. |
| Replication |
Replicates data to multiple database servers at any given point in time, for database redundancy.† |
High availability of databases |
| Automatic failover |
In case the primary database server fails, automatically switches to the standby server to continue operation. |
| Online recovery |
Restores or adds database servers without stopping operation. |
| Watchdog |
Links multiple instances of pgpool-II, performs heartbeat monitoring, and shares server information. When failure occurs, a switch is conducted autonomously. |
High availability of pgpool-II |
†: pgpool-II can use its own replication capabilities or those provided by other software, but it is often recommended to use PostgreSQL's streaming replication. Streaming replication is a feature that replicates databases by shipping transaction logs (WALs) of
PostgreSQL (primary) to multiple instances of
PostgreSQL (standby). This capability is explained in the article "
What is streaming replication, and how can you set it up?".
Streaming replication
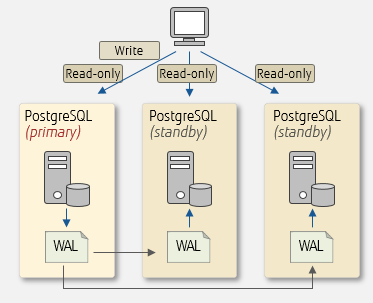
Diagram illustrating streaming replication
Load balancing and connection pooling
Scale-out is one way to increase the processing capacity of the entire database system by adding servers. PostgreSQL allows you to scale out using streaming replication. Efficiently distributing queries from applications to database servers is essential in this scenario. PostgreSQL itself does not have a distribution feature, but you can utilise load balancing of pgpool-II, which efficiently distributes read-only queries in order to balance workload.
Another great pgpool-II feature is connection pooling. By using connection pooling of pgpool-II, connections can be retained and reused, reducing the overhead that occurs when connecting to database servers.
Load balancing and connection pooling
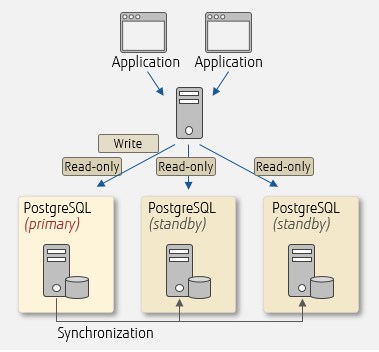
To use these features, you need to set the relevant parameters in pgpool.conf.
Automatic failover and online recovery
This section describes automatic failover and online recovery using pgpool-II. The explanation assumes that streaming replication of PostgreSQL is used.
The diagram below illustrates how pgpool-II perform automatic failover when it detects an error in PostgreSQL (primary).
Automatic failover using pgpool-II
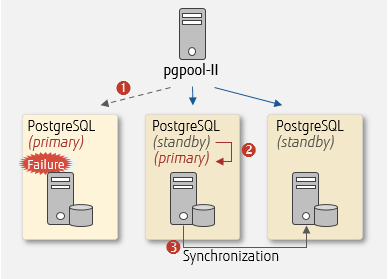
- Detach the failed primary server and stop query distribution from pgpool-II
- Promote the standby server to a new primary server
- Change the sync location of the replication for each PostgreSQL
Note that you need to create scripts for 2 and 3 beforehand and set them in pgpool-II.
The online recovery feature executes the online recovery command from pgpool-II and reinstates the detached old PostgreSQL (primary) as a PostgreSQL (standby). The command operations are described below.
Online recovery using pgpool-II
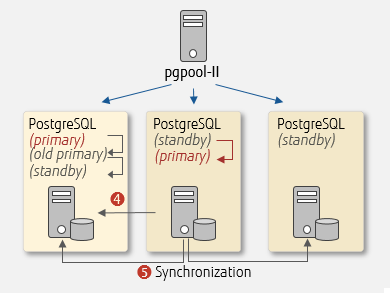
- Rebuild the old PostgreSQL (primary) based on data of the newPostgreSQL (primary) and reinstate it as a PostgreSQL (standby)
- Change the sync location of the replication for each PostgreSQL
You will need to create scripts for these processes beforehand and store them on the database server side.
Note
The online recovery feature of pgpool-II must be installed as an extended feature for PostgreSQL on the database server side.
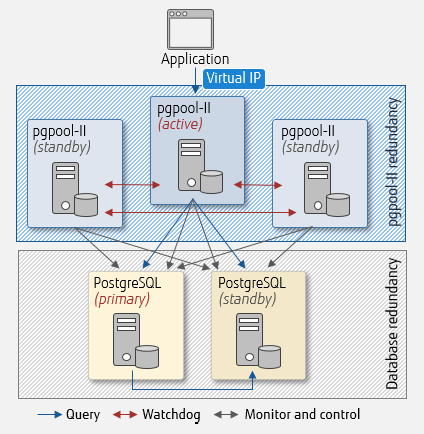
Watchdog
In order to implement high availability of the entire system, pgpool-II itself also needs to be made redundant. This feature for this redundancy is called Watchdog.
Here is how it works. Watchdog links multiple instances of pgpool-II in an active/standby setup. Then, the linked pgpool-II instances perform mutual hearbeat monitoring and share server information (host name, port number, pgpool-II status, virtual IP information, startup time). If pgpool-II (active) providing the service fails, pgpool-II (standby) autonomously detects it and performs failover. When doing this, the new pgpool-II (active) starts a virtual IP interface, and the old pgpool-II (active) stops its virtual IP interface. This allows the application side to use pgpool-II with the same IP address even after the switch of the servers. By using Watchdog, all instances of pgpool-II work together to perform database server monitoring and failover operations - pgpool-II (active) works as the coordinator.
Using watchdog with pgpool-II
pgpool.conf needs to be set up accordingly for these operations.
In a redundant configuration, we also need to take into account the possible consequences of split brain of both pgpool-II and database (PostgreSQL). Split brain is a situation where multiple active servers exist. Updating data during this state will result in data inconsistency and recovery will become onerous. To avoid a split brain, it is recommended to configure pgpool-II with 3 or more servers, and to have an odd number of servers. Below are examples of when split brains may happen:
- Split brain of pgpool-II
When 2 instances of pgpool-II are set up and an error occurs only in the network connecting these pgpool-II instances - failover will not occur, but coordination of pgpool-II will stop.
- Split brain of the database (PostgreSQL)
When 2 instances of pgpool-II are set up and an error occurs in the network that connects pgpool-II (active) and PostgreSQL (primary). In 2-instance setups, voting to judge failover (described later) will not take place.
Now, let's take a look at an example where Watchdog averts the occurrence of split brain in the database when there are 3 instances of pgpool-II:
Network failure - fault detection and voting
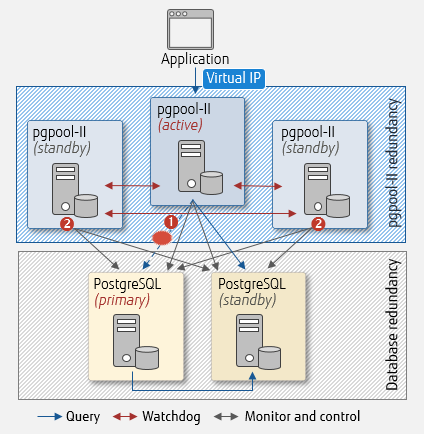
Using Watchdog with pgpool-II - network failure
- pgpool-II (active) detects a failure caused by a disconnection in the network between itself and PostgreSQL (primary), but cannot cannot determine whether PostgreSQL (primary) is running.
- Other instances of pgpool-II (standby) vote to judge failover
After that, the instances of pgpool-II decide take action:
Network failure - decision and action
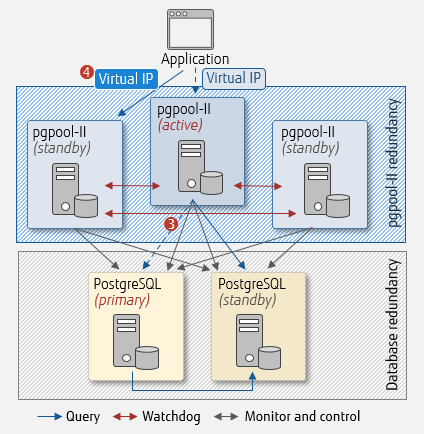
Using Watchdog with pgpool-II
- There is no failover because it was not the majority vote. Here, split brain is avoided. pgpool-II (active) fences PostgreSQL (primary) to stop query distribution
- If a failure is detected on pgpool-II (active), connection is switched to pgpool-II (standby)
As a result, update queries from the application side can continue to run.
System setup using pgpool-II
Here we present a system setup based on real-life business and perform a simple operation check.
System setup
We will design a sample system setup that meets the following requirements, assuming an actual business scenario that utilise pgpool-II:
- High availability setup with consideration to split brain
- Future scale-out
- Load balancing and connection pooling to improve performance
Generally, to select hardware and software, we analyze cost performance and aim for a simple and efficient setup. In doing so, the first factor is the allocation of pgpool-II. The table below is a summary of the possible locations and how they affect the system:
| Location |
Server load |
Network |
Server cost (quantity) |
| Dedicated server |
Not affected by other software. |
Affected by networks:
- Connection between the application and pgpool-II
- Connection between pgpool-II and the database
|
An additional server to operate pgpool-II is required.
We recommend to prepare an odd number of servers, starting from 3.
|
| Database server (coexisting) |
Affected by the performance of the coexisting database.
Redundancy and scalability of the server require consideration.
|
Little network impact.
A part of the connection between pgpool-II and the database can be local.
|
We recommend 3 or more coexisting pgpool-II servers.
More servers are required additionally, depending on the number of available database servers.
|
| Application server or web server (coexisting) |
Affected by the performance of the coexisting software.
Redundancy and scalability of the server require consideration.
|
No network impact.
The application (web server) and pgpool-II can be connected locally.
|
We recommend 3 or more coexisting pgpool-II servers.
More servers are required additionally, depending on the number of available application servers or web servers.
|
pgpool-II coexisting on database servers
First, let's look at a configuration setup where pgpool-II coexists on a database server.
We assume a practical system setup that can be used in an actual business case. As illustrated below, requests from clients are distributed by a load balancer, and the applications are running in parallel on 3 application servers.
Multiple instances of pgpool-II will work together with Watchdog. Add PostgreSQL (standby) to database server 3 for scale-out, and then more servers as required.
In this setup, note that the workload concentrates on the database server where pgpool-II (active) runs. Take this into account when working out load balance.
pgpool-II coexisting on database servers
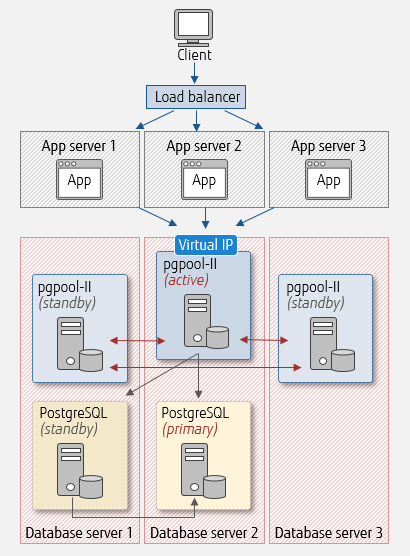
Example pgpool-II configuration
pgpool-II coexisting on application servers
Next, let's look at a sample setup where pgpool-II coexists on application servers. pgpool-II now operatea in a multi-master configuration, so a fixed IP is assigned. Benefits are as follows.
- Load balancing of pgpool-II
- Update and read-only queries are accepted on pgpool-II (active) and pgpool-II (standby)
- Reduced network overhead between applications and pgpool-II
Notice that pgpool-II (active) remains the coordinator to control the database, even in a multi-master configuration. Add a 3rd database server and more for scale-out.
pgpool-II coexisting on application servers
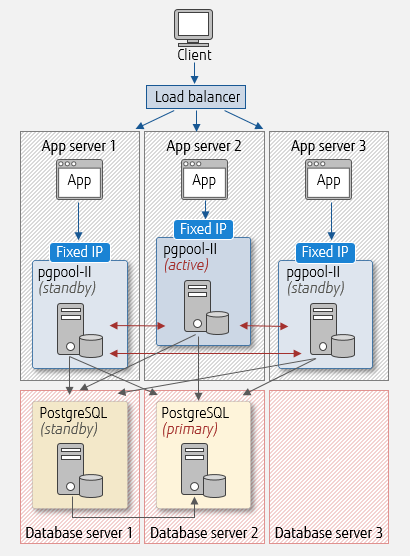
Example pgpool-II configuration
Operation check
Let's check automatic failover and online recovery in a setup where pgpool-II coexists on application servers. It is assumed that PostgreSQL and pgpool-II have been installed, configured, and started. The example uses the following:
- host0: host of database server 1
- host1: host of database server 2
- host5: host of application server 1 where pgpool-II (active) runs
1Connect to pgpool-II (active) on application server 1 and check the status of the database server.
$ psql -h host5 -p 9999 -U postgres
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | up | 0.500000 | primary | 2 | false | 0 | 2020-08-27 14:43:54
1 | host1 | 5432 | up | 0.500000 | standby | 2 | true | 0 | 2020-08-27 14:43:54
(2 rows)
2Force PostgreSQL (primary) on database server 1 (host0) to stop.
$ pg_ctl -m immediate stop
3From application server 1, check the database server status again.
The first connection will fail, but the second connection will succeed, because the connection to the database will be restored after a reset.
Note that the status of host0 has changed to "down", and roles have been swapped. We just confirmed that the failover to host1 was done automatically, and it has been promoted to primary.
postgres=# SHOW pool_nodes;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | down | 0.500000 | standby | 2 | false | 0 | 2020-08-27 14:47:20
1 | host1 | 5432 | up | 0.500000 | primary | 2 | true | 0 | 2020-08-27 14:47:20
(2 rows)
4From application server 1, execute the online recovery command for database server 1 (host0).
Confirm that it has completed normally.
$ pcp_recovery_node -h host5 -p 9898 -U postgres -n 0
Password: (yourPassword)
pcp_recovery_node -- Command Successful
5From application server 1, check the database server status again.
After online recovery, the connection will be reset on the first connection to the database, and the second connection will succeed. Since the status of host0 has changed to "up", you can see that it has recovered and became standby.
postgres=# SHOW pool_nodes;
ERROR: connection terminated due to online recovery
DETAIL: child connection forced to terminate due to client_idle_limitis:-1
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | up | 0.500000 | standby | 2 | true | 0 | 2020-08-27 14:50:13
1 | host1 | 5432 | up | 0.500000 | primary | 2 | false | 0 | 2020-08-27 14:47:20
(2 rows)
Notes
We have seen that pgpool-II is an effective open source extension of PostgreSQL for enterprise use. It is suitable for medium and large scale systems that have a large number of simultaneous connections and require scale-out.
Be sure to note the following when adopting pgpool-II:
- There are numerous configuration settings required to build an environment, and required scripts must be created by the user.
Thoroughly examine and verify design and environment setup.
- Only read-only queries are distributed in load-balancing.
Performance improvement is not seen in systems that handle many update queries. Similarly, read-only performance improves as the number of database servers increases, but update performance may deteriorate.
Fujitsu Enterprise Postgres is an enterprise-grade database based on PostgreSQL, and bundles pgpool-II among other popular open source extensions. Fujitsu Enterprise Postgres also has the following features.
- Application connection switching
This is a client-side feature that switches the connection to databases while being unaware of the primary/standby role of servers.
- Database multiplexing
This feature runs on streaming replication. When failures are detected in database processes, disks, and networks, automatic disconnection and failover is executed.
The features of pgpool-II and Fujitsu Enterprise Postgres that provide similar functionalities cannot be used concurrently. It is however possible to use features providing different functionalities, such as using the load balancing and connection pooling of pgpool-II in conjunction with database multiplexing of Fujitsu Enterprise Postgres.







