

Fujitsu Enterprise Postgres' High-Speed Data Load leverages the PostgreSQL COPY command by running it in parallel using as many workers as your available resources allow. This feature means you can perform bulk data load using as many parallel processes as possible, according to the number of cores and CPU availability. It's an approach that ensures your data load process makes the best use of available resources, without the need to pre-configure and tune your environment beforehand.
Overview
Mission-critical systems can now take advantage of multi-core technology. So it's essential that bulk data load tools use as much of the available resources as possible.
The High-Speed Data Load feature inside Fujitsu Enterprise Postgres sends data from the input file to several parallel workers, each of which simultaneously performs data conversion, table creation, and index creation, thus reducing load time.
Bulk data load performance gain
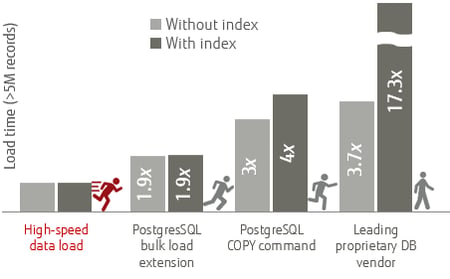 The gains are significant. Of course, bulk data load tools improve performance when compared to the execution of thousands or millions of INSERT statements. However, as seen in the diagram, even when compared to other bulk data load solutions, Fujitsu Enterprise Postgres High-Speed Data Load is one of the fastest, both for indexed and non-indexed data load.
The gains are significant. Of course, bulk data load tools improve performance when compared to the execution of thousands or millions of INSERT statements. However, as seen in the diagram, even when compared to other bulk data load solutions, Fujitsu Enterprise Postgres High-Speed Data Load is one of the fastest, both for indexed and non-indexed data load.
It executes the PostgreSQL COPY command using a degree of multiple parallel workers determined automatically at the time of execution based on resource availability. As such, data is loaded at high speed into Fujitsu Enterprise Postgres tables. Each worker serially performs the tasks of data conversion, table creation, and index creation for ultimate performance gains of between three and four times faster than using the COPY command alone.
An even more significant gain in performance
Performance can be improved even furhter by making High-Speed Data Load part of the same transaction as an earlier CREATE TABLE or TRUNCATE with the write-ahead log (WAL) parameter wal_level set to minimal, because no WAL records are generated.
Download the white paper for specific instructions >>>
If you are assessing database management systems to support your digital transformation and unlock the value in your data, then call our database experts to answer your questions should you be considering a migration or new application development.

